
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP資料探勘中的資料預處理
資料預處理是資料探勘中一個重要的過程。在這個過程中,原始資料被轉換為可理解的格式,併為進一步分析做好準備。其目的是提高資料質量,並使其達到特定任務的要求。
資料預處理中的任務
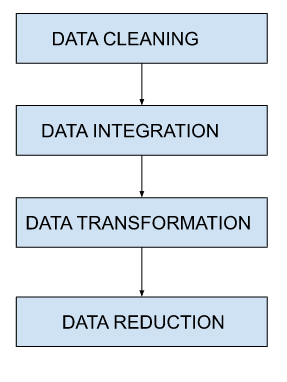
資料清洗
資料清洗幫助我們從資料集中刪除不準確、不完整和不正確的資料。一些用於資料清洗的技術包括:
處理缺失值
當某些資料丟失時,就會出現這種情況。
可以使用標準值以手動方式填充缺失值,但僅適用於小型資料集。
分別可以使用屬性的平均值和中位數來替換資料在正態分佈和非正態分佈中的缺失值。
如果資料集很大並且元組中缺少許多值,則可以忽略元組。
在使用迴歸或決策樹演算法時,可以使用最合適的數值。
噪聲資料
噪聲資料是指機器無法解釋且包含不必要的錯誤資料的資料。處理它們的一些方法包括:
分箱法 - 此方法處理噪聲資料以使其平滑。資料被平均劃分並以分箱的形式儲存,然後應用方法來平滑或完成任務。這些方法包括按分箱平均值平滑(分箱值被平均值替換)、按分箱中位數平滑(分箱值被中位數替換)以及按分箱邊界平滑(取最小/最大分箱值並替換為最接近的邊界值)。
迴歸 - 迴歸函式用於平滑資料。迴歸可以是線性迴歸(包含一個自變數)或多元迴歸(包含多個自變數)。
聚類 - 它用於將相似資料分組到叢集中,並用於查詢異常值。
資料整合
將來自多個來源(資料庫、電子表格、文字檔案)的資料組合到單個數據集中。在這個過程中建立了資料的一個單一且一致的檢視。資料整合過程中的主要問題包括模式整合(整合從各種來源收集的資料集)、實體識別(識別來自不同資料庫的實體)以及檢測和解決資料值概念。
資料轉換
在本部分中,更改資料的格式或結構,以便將資料轉換為適合挖掘過程的格式。資料轉換方法包括:
歸一化 - 將資料縮放以將其表示在特定較小範圍內(-1.0 到 1.0)的方法。
離散化 - 它有助於減少資料量,並將連續資料劃分為區間。
屬性選擇 - 為了幫助挖掘過程,從給定的屬性中派生出新的屬性。
概念層次生成 - 在此,屬性從層次結構中的較低級別更改為較高級別。
聚合 - 在此,儲存資料的摘要,這取決於資料的質量和數量,以使結果更佳。
資料規約
它有助於提高儲存效率並減少資料儲存,從而透過產生幾乎相同的結果來簡化分析。在處理海量資料時,分析變得更加困難,因此使用規約來解決這個問題。
資料規約的步驟包括:
資料壓縮
壓縮資料以進行有效的分析。無失真壓縮是指在壓縮過程中沒有資料丟失。有失真壓縮是指在壓縮過程中刪除不必要的資訊。
數值規約
減少資料量,即僅儲存資料的模型而不是整個資料,這提供了資料的較小表示,而不會丟失任何資料。
降維
在此,減少屬性或隨機變數,以便使資料集維度降低。屬性被組合而不會丟失其原始特徵。
結論
本文包含資料預處理,它有助於將資料轉換為可用的格式。有助於資料預處理的任務包括資料清洗、資料整合、資料轉換和資料規約。資料清洗透過處理缺失值並藉助分箱法、迴歸和聚類平滑噪聲來刪除不完整的資料。資料整合將來自多個來源的資料組合成一個數據集。資料轉換透過使用離散化、屬性選擇、概念層次生成和聚合來幫助更改資料的格式,從而使資料可用於挖掘。資料規約有助於減少資料的儲存,從而透過一些步驟(如資料壓縮、數值規約和降維)使分析更容易。

20K+ 瀏覽量
