
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPSeaborn能否用於執行資料的計算,例如均值或標準差?
Seaborn主要是一個數據視覺化庫,它不提供直接執行資料計算的方法,例如計算均值或標準差。但是,Seaborn可以與pandas庫無縫協作,pandas是Python中一個強大的資料處理庫。您可以使用pandas對資料進行計算,然後使用Seaborn視覺化計算結果。
均值是一種統計度量,表示一組數字的平均值。它是透過將集合中的所有數字加起來,然後將總和除以數字的總數來計算的。
標準差是一種統計度量,用於量化一組值中的離散度或可變性。
透過結合pandas的資料處理功能來對資料進行計算,以及Seaborn的視覺化功能,我們可以從資料中獲得見解,並透過視覺化有效地傳達我們的發現。
以下是關於如何結合使用Seaborn和pandas對資料進行計算的詳細說明。
匯入必要的庫
首先,在Python環境中匯入所有必需的庫,例如seaborn和pandas。
import seaborn as sns import pandas as pd
將資料載入到pandas DataFrame中
接下來,我們必須使用pandas庫中的read_csv()函式載入資料集。
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
使用pandas執行計算
Pandas提供了各種方法和函式來對資料執行計算。以下是一些我們可以使用pandas執行的常見計算示例
計算列的均值
要計算特定列的均值,pandas庫中具有mean()函式。
示例
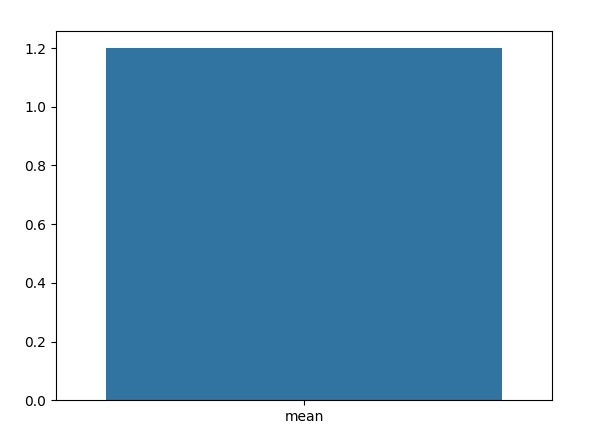
mean_value = df['petal.width'].mean()
print("The mean of the petal.width column:",mean_value)
輸出
The mean of the petal.width column: 1.199333333333334
計算列的標準差
要計算列的標準差,pandas庫中有一個名為std()的函式。
示例
std_value = df['petal.width'].std()
print("The standard deviation of the petal.width column:",std_value)
輸出
The standard deviation of the petal.width column: 0.7622376689603465
計算列的總和
pandas中有一個名為sum()的函式,用於計算列的總和。
sum_value = df['petal.width'].sum()
print("The sum of the petal.width column:",sum_value)
以上只是一些示例,pandas提供了廣泛的方法來執行計算,包括聚合、統計函式等等。
使用Seaborn視覺化計算結果
使用pandas對資料進行計算後,我們可以使用Seaborn視覺化計算結果。Seaborn提供了各種繪圖函式,這些函式接受pandas Series或DataFrame物件作為輸入。
我們可以使用各種其他的Seaborn繪圖函式來視覺化我們的計算結果,例如箱線圖、小提琴圖、點圖等等。Seaborn提供了許多自定義選項來增強我們資料的視覺表示。
示例
在這個例子中,我們使用Seaborn的'barplot()'函式來建立均值的條形圖。'x'引數表示x軸標籤,'y'引數表示計算出的均值。
#Create a bar plot of the mean values sns.barplot(x=['mean'], y=[mean_value])
輸出
注意
雖然Seaborn本身不提供直接的計算方法,但它利用了pandas強大的資料處理和計算能力。因此,在使用Seaborn視覺化資料之前,瞭解pandas及其功能來對資料執行高階計算非常重要。

瀏覽量:330
