
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP機器學習專業人士面臨的七大挑戰
本文讓我們瞭解當今機器學習工程師面臨的一些常見挑戰。
引言
如今,機器學習已成為各個領域和行業的尖端技術,機器學習從業人員的數量大幅增加,從概念設計到將概念付諸生產,實施人工智慧專案的挑戰也隨之增大。機器學習工程師的道路並非易事,他們/她們會在這個過程中面臨許多挑戰。
高質量資料收集
是的,這是事實。我們不能否認,如今資料已成為每個行業的“新石油”。資料對他們來說是金子。資料在每個用例中都扮演著關鍵角色。機器學習工程師60%的工作在於收集資料。但實際情況與表面上看到的略有不同。高質量的真實資料稀缺。我們為行業ML收到的資料大多充滿了噪聲和異常值。這些噪聲資料必須經過嚴格的清洗過程,有時會佔用整個任務的約50%。工程師有時可能會幸運地從來源良好且開發完善的API獲取資料,這些API可以提供有用的資料,但大多數時候他們必須依賴來自爬蟲、網站、感測器等的資料,這些資料可能包含大量的噪聲。對高質量資料的需求正在呈指數級增長。
訓練資料不足
我們可能從外部來源或內部資料收集方法獲得的資料可能高度不足或過少,無法開發出具有良好效能的高質量模型。訓練資料的稀缺直接影響模型在新/未見資料上的效能,這樣的模型可能不適合用於生產。
例如,假設我們想訓練一個線性迴歸模型來預測給定組織中員工在提供某些引數的情況下獲得的工資。假設該組織的員工人數非常少(約50人)。在這裡我們可以說,我們無法建立一個好的模型,因為我們沒有很多資料點讓模型學習。這裡資料稀缺。
欠擬合問題
這是機器學習工程師面臨的一個非常常見的問題。這也可能是訓練資料不足的直接後果。如果資料變化較少,也可能發生這種情況。或者如果我們在清洗過程中刪除了很大一部分資料,並且剩下的資料不多。在欠擬閤中,模型的訓練甚至在訓練集上表現也不好,因此它無法泛化並在未見資料上進行良好的預測。
例如,在上一個預測員工工資的案例中,使用該資料的工程師可能會在LR模型中遇到欠擬合問題。
不相關和不需要的特徵
很多時候,ML工程師獲得的資料可能包含大量不相關特徵的資料集,如果資料集中有很大一部分是不相關的特徵,那麼訓練模型就會變得非常麻煩。
例如,在計算一個人工資的用例中,員工姓名或員工ID是不相關的特徵,因為模型(線性迴歸)可能不需要這些特徵,因為它們是分類的,並且可能不被主要採用數值的迴歸模型接受。
過擬合問題
與欠擬合類似,存在過擬合問題,其中模型可以在訓練資料上產生良好的結果,但無法很好地泛化到未見資料或測試集。因此,該模型被認為具有很大的高方差誤差和低偏差。具有高方差的模型可以準確地表示資料集,但可能導致過擬合到噪聲或其他不具有代表性的訓練資料,並且模型的準確性降低。當模型學習到訓練資料集中的噪聲或隨機波動被模型當作概念學習和掌握時,就會發生過擬合。
例如
假設我們要對成年人的年齡與識字率進行建模。如果我們對很大一部分人口進行抽樣,我們會發現一種明確的關係。這是訊號,而噪聲干擾訊號。如果我們對當地人口進行相同的操作,這種關係就會變得模糊。它會受到異常值和隨機性的影響,例如,一個成年人很早就上學了,或者一些成年人負擔不起教育等等。
模型部署
資料顯示,大多數生產中的機器學習專案在第一次部署時都失敗了,這些專案在本地伺服器/系統上看起來執行良好。ML專案需要大量的雲資源,例如資料倉庫、資料清洗管道、虛擬機器、排程程式等。這些元件的無縫整合對於機器學習和MLOps工程師來說是一項具有挑戰性的任務。這項任務需要大量的實踐和依賴關係、對底層模型與業務的低理解、對業務問題的理解以及不穩定的模型。
例如,AWS、Azure和Google等許多雲服務都有自己的雲ML訓練和部署管道,我們可以將其用於我們的用例。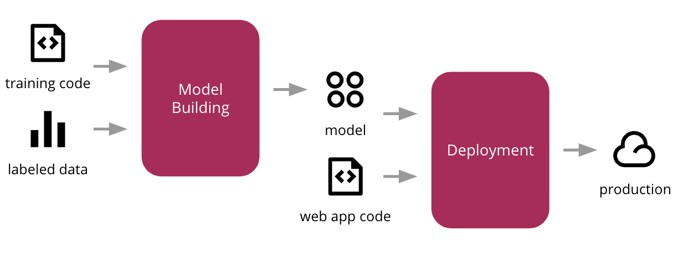
監控和再訓練方法
ML模型的監控是一項非常重要的任務,工程師有時難以維護和監控模型的效能和指標、故障原因、分析等。此外,一旦訓練好模型,如果效能下降或收到更高質量或更新的資料,將來可能需要對其進行再訓練。
例如,有很多基於伺服器的監控平臺,例如W&B、Neptune.ai。
結論
機器學習是一項複雜的任務,伴隨著相當多的挑戰。它需要在資料分析、程式設計熟練程度、對機器學習以及部署的良好理解等許多領域具備技能。

978 次瀏覽
