
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Pandas 處理日期和時間
Python 資料分析和處理的核心部分是使用 Pandas 處理日期和時間。強大的 Pandas 庫提供了有效的方法來處理和檢查時間序列資料。它提供了一個 DateTimeIndex,可以輕鬆地索引 DataFrames 並對其執行基於時間的操作。使用者可以透過將字串或其他表示形式轉換為 Pandas DateTime 物件來為其資料構建 DateTimeIndexes,從而簡化時間感知分析。該庫支援重新取樣、時間膨脹和日期範圍建立,從而簡化了基於時間的資料的組合和處理。此外,Pandas 還支援管理時區,從而能夠進行大資料分析的 timestamp 轉換和轉換。
安裝命令
在使用 Pandas 之前,必須在您的計算機系統上安裝它。使用 Python 的包管理器 pip,執行以下命令:
pip install pandas
Pandas 的特性
DataFrame:DataFrame 是 Pandas 引入的一個新特性,它是一個二維標記資料結構,類似於電子表格或 SQL 表。它允許有效地管理行和列中的資料,並促進各種資料操作。
Series:Series 是一維標記陣列,具有類似於列表或 NumPy 陣列的附加功能。Series 充當 DataFrames 的基本單元,可以儲存各種資料型別。
資料對齊:即使資料來自多個來源,Pandas 也會根據標籤自動對齊資料,因此資料操作(如算術運算)也能正確執行。
資料清洗:Pandas 提供了各種處理缺失資料的方法,例如 dropna(),它刪除 NaN 值,以及 fillna(),它使用指定的方法填充缺失值。
資料重塑:藉助 Pandas 提供的靈活工具,使用者可以使用 pivot_table()、melt() 和 stack()/unstack() 方法輕鬆地重塑資料。
分組和聚合:Pandas 提供的 groupby() 方法允許使用者根據特定標準將資料分成組,然後對每個組應用聚合函式,例如 sum、mean、max 等。
合併、連線和串聯:Pandas 透過 merge()、join() 和 concat() 等方法,使得可以無縫地整合和合並來自多個來源的資料。
時間序列分析:Pandas 提供了廣泛的功能來處理時間序列資料,包括日期範圍構建、基於時間的索引以及以不同頻率重新取樣。
資料 I/O:Pandas 可以讀取和寫入多種不同格式的資料,例如 CSV、Excel、SQL 資料庫等。
基於標籤的索引:Pandas 的多功能性和使用者友好性,使得根據標籤或條件輕鬆地切片、選擇和更新資料。
資料視覺化:Pandas 本身不處理資料視覺化,但它可以輕鬆地與其他庫(如 Matplotlib 和 Seaborn)互動,允許使用者使用 Pandas 資料建立有用的圖表和圖形。
使用 Pandas 的基本程式
建立 DataFrame
建立 DateTimeIndex 和重新取樣
過濾資料
建立 DataFrame
在基於 Python 的資料分析和處理中,建立一個 Pandas DataFrame 是一個關鍵步驟。Pandas 作為一個強大的庫,提供了一個稱為 DataFrame 的二維標記資料結構,類似於電子表格或 SQL 表。Pandas 允許將資料組織成行和列,從而簡化資料管理和分析。
演算法
匯入 Pandas 庫。
準備打算在 DataFrame 中使用的資料。您可以使用字典、字典列表、列表列表或 NumPy 陣列。
使用 pd.DataFrame() 建構函式建立 DataFrame。將資料以及任何可選引數(包括列名和索引)傳遞給建構函式。
您可以選擇使用 pd.DataFrame() 建構函式的 index 引數設定索引,使用 columns 引數設定列名。
現在 DataFrame 可用於編輯和資料分析。
示例
import pandas as pd
data_dict = {
'Name': ['Rahul', 'Anjali', 'Siddharth'],
'Age': [15, 33, 51],
'City': ['Mumbai', 'Goa', 'Jammu']
}
df1 = pd.DataFrame(data_dict)
dataListOfDicts = [
{'Name': 'Komal', 'Age': 25, 'City': 'Pune'},
{'Name': 'Bulbul', 'Age': 30, 'City': 'Agra'},
{'Name': 'Aarush', 'Age': 35, 'City': 'Meerut'}
]
df2 = pd.DataFrame(dataListOfDicts)
data_list_of_lists = [
['Anmol', 27, 'Hyderabad'],
['Tarun', 20, 'Mumbai'],
['Srijan', 31, 'Chandigarh']
]
df3 = pd.DataFrame(data_list_of_lists, columns=['Name', 'Age', 'City'])
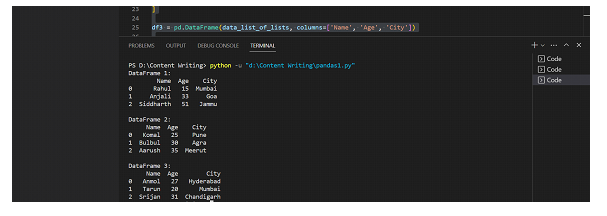
print("DataFrame 1:")
print(df1)
print("\nDataFrame 2:")
print(df2)
print("\nDataFrame 3:")
print(df3)
輸出
建立 DateTimeIndex 和重新取樣
在基於 Python 的資料分析和處理中,建立一個 Pandas DataFrame 是一個關鍵步驟。Pandas 作為一個強大的庫,提供了一個稱為 DataFrame 的二維標記資料結構,類似於電子表格或 SQL 表。Pandas 允許將資料組織成行和列,從而簡化資料管理和分析。
演算法
匯入 Pandas 庫。
準備一個包含日期或時間戳列的 DataFrame 資料。
使用 pd.to_datetime() 將日期或時間戳列轉換為 Pandas DateTimeIndex。
使用 set_index() 函式將 DateTimeIndex 設定為 DataFrame 的索引。
使用 resample() 方法將資料重新取樣到不同的頻率後,您可以使用聚合函式(如 mean、sum 等)來獲取新頻率的值。
示例
import pandas as pd
data = {
'Date': ['2023-07-25', '2023-07-26', '2023-07-27', '2023-07-28', '2023-07-29'],
'Value': [10, 15, 8, 12, 20]
}
df = pd.DataFrame(data)
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
monthly_data = df.resample('M').mean()
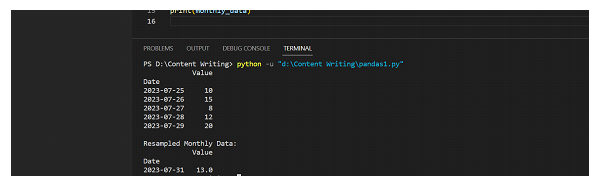
print(df)
print("\nResampled Monthly Data:")
print(monthly_data)
輸出
過濾資料
Pandas 提供了強大的基於布林索引的資料過濾功能。使用者可以透過構建帶有應用於 DataFrame 列的條件的布林掩碼,快速選擇滿足過濾條件的行。資料分析師可以使用此方法專注於相關資訊,調查趨勢,查詢模式並對特定資料子集進行進一步研究。
演算法
匯入 Pandas 庫。
資料準備可以在 DataFrame 中完成,或者例如從 CSV 檔案讀取資料。
結合布林索引和條件來根據特定要求過濾資料。
將條件應用於一個或多個 DataFrame 列以建立布林掩碼。
使用布林掩碼選擇滿足過濾條件的行。
示例
import pandas as pd
data = {
'Name': ['Arushi', 'Shobhit', 'Tarun', 'Dishmeet', 'Evan'],
'Age': [25, 30, 35, 28, 40],
'City': ['Mumbai', 'Delhi', 'Goa', 'Bareilly', 'Agra']
}
df = pd.DataFrame(data)
filtered_df = df[df['Age'] > 30]
print(filtered_df)
輸出
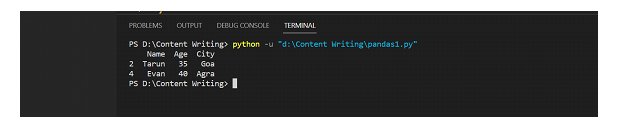
結論
Python 的 Pandas 庫簡化了時間和日期的處理,用於時間資料的處理。藉助 Pandas 的 DateTimeIndex 和函式,使用者可以有效地執行基於時間的索引、重新取樣和時區管理。該庫的靈活性使日期計算、過濾和時間序列視覺化更加容易。它與其他 Python 工具的無縫整合增強了資料探索和操作。從銀行和經濟學到天氣預報和社會趨勢分析,Pandas 在各種應用中對於處理和分析與時間相關的資料至關重要。它使分析師能夠獲得有見地的知識。

241 次瀏覽
