
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP計算機體系結構中的並行解碼是什麼?
如圖所示,標量處理器每個週期只能解碼一條指令。此外,流水線處理器必須檢查依賴關係,以確定是否可以發出該指令。相比之下,超標量處理器必須執行一項複雜得多的任務。
如圖所示,它必須在一個時鐘週期內解碼多條指令,例如四條指令。它還需要從兩個方面檢查依賴關係:首先,要發出的指令是否依賴於當前正在執行的指令;其次,候選指令之間是否存在依賴關係。
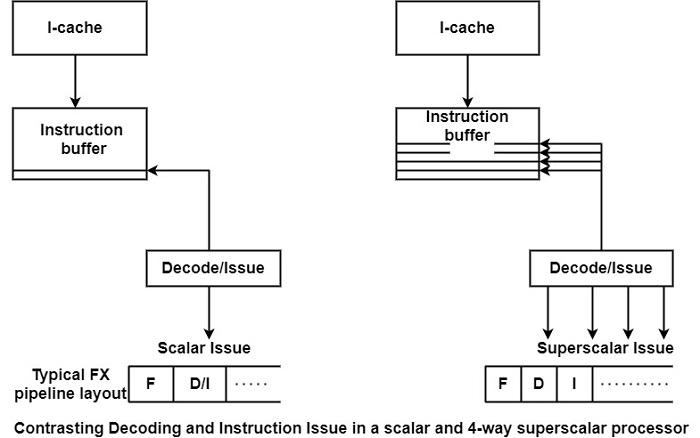
由於超標量處理器比標量處理器擁有更多的執行單元 (EU),因此執行指令的數量遠高於標量處理器的情況。這意味著在依賴性檢查過程中必須執行更多比較。超標量處理器的解碼-發出路徑比標量處理器更關鍵,因為它關係到能否達到較高的時鐘頻率。
超標量處理器傾向於使用兩個、甚至三個或更多個流水線週期來解碼和發出指令。例如,PowerPC 601、PowerPC 604 和 UltraSparc 需要 2 個週期,而 α 21064 需要 3 個週期,PentiumPro 甚至需要 4.5 個週期。解決這個問題的一種方法是透過**預解碼**。
預解碼將部分解碼任務轉移到片上指令快取 (I-cache) 的載入階段,如圖所示。

在此,在載入 I-cache 的同時,一個稱為預解碼單元的專用單元執行部分解碼,並將多個解碼位連線到每條指令。例如,在 RISC 處理器的情況下,通常附加 4-7 位,這些位指示:
指令類別
執行所需資源的型別,以及
在某些處理器中,甚至包括分支目標地址已在預解碼期間計算的事實,例如 Hal PM1 或 UltraSparc。
預解碼單元的數量如表所示。
使用的預解碼位數
| 首批批次發貨的型別/年份 | 附加到每條指令的預解碼位數 |
|---|---|
| PA 7200 (1995) | 5 |
| PA 8000 (1996) | 5 |
| PowerPC 620 (1996) | 7 |
| UltraSparc (1995) | 4 |
| HAL PM1 (1995) | 4 |
| AMD K5 (1995) | 5 |
| R10000 (1996) | 4 |
對於像 AMD K5 這樣的 CISC 處理器,預解碼可以確定指令的起始或結束位置、操作碼和字首的位置等等。這需要相當多的額外位。K5 為每個位元組新增五個額外位。因此,在這種情況下,指令快取需要超過 70% 的額外儲存空間。
預解碼用於縮短總週期時間或減少解碼和指令發出所需的週期數。例如,PowerPC 620、R10000 和 Hal 的 PM1 的預解碼只需要一個週期即可完成解碼和發出。

2K+ 次瀏覽
