
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP計算機體系結構中的多共享匯流排是什麼?
單個共享匯流排的頻寬有限,這在構建可擴充套件的多處理器方面是一個主要限制。有多種方法可以增加互連網路的頻寬。一個自然的想法是增加匯流排的數量,就像處理器和記憶體單元一樣。已經提出了四種不同的方法來連線匯流排到處理器、記憶體單元和其他匯流排,如下所示:
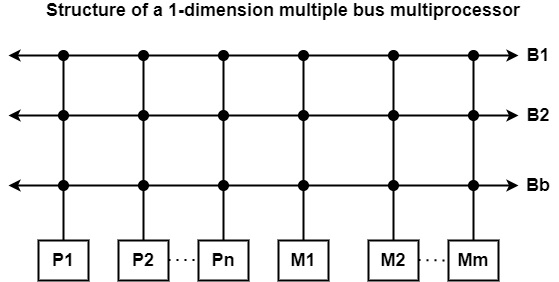
一維多匯流排系統 - 向多匯流排系統擴充套件單匯流排系統的最簡單方法是一維多匯流排系統,如圖所示。這種方法導致了一個典型的統一記憶體訪問(UMA)機器,其中任何處理器都可以透過任何匯流排訪問任何記憶體單元。
在這種系統中,使用 1-of-N 仲裁器是不夠的。在 1 維多匯流排系統中,仲裁是一個兩階段的過程。首先,1-of-n 仲裁器(每個記憶體單元一個)可以解決多個處理器需要對相同共享記憶體單元進行獨佔訪問時的衝突。
在第一階段之後,m(n 箇中的)個處理器可以訪問其中一個記憶體單元。但是,當多個匯流排 (b) 少於記憶體單元的數量 (m) 時,需要進行第二階段的仲裁,其中使用額外的 b-of-m 仲裁器來為那些強烈請求訪問記憶體單元的處理器分配匯流排。
二維或三維匯流排系統 - 一維多匯流排的進一步推廣是引入第二和第三維。在這些系統中,多條匯流排構成一個網格互連網路。每個處理器節點都連線到一個行匯流排和一個列匯流排。
同一行或同一列的處理器構成一個傳統的單匯流排多處理器。記憶體可以以多種方式分佈。最傳統的方法是將記憶體單元連線到每條總線上。這些體系結構的主要問題是維護快取一致性。
叢集匯流排系統 - 將多條匯流排引入多處理器的第三種方法是叢集架構,它表示了一種 NUMA 機器的概念。叢集架構的主要思想是,單個匯流排多處理器(稱為叢集)透過更高級別的匯流排連線。每個叢集都有其本地記憶體。
本地叢集記憶體的訪問時間遠小於遠端叢集記憶體的訪問時間。將程式碼和堆疊儲存在叢集記憶體中可以顯著減少訪問遠端叢集記憶體的需要。但是,事實證明,如果沒有快取支援,這種結構無法避免高級別總線上的交通擁堵。
分層匯流排系統 - 單匯流排系統的另一種自然推廣是分層匯流排系統,其中單個匯流排“超級節點”透過更高級別的快取或“超級快取”連線到更高級別的匯流排。

2K+ 瀏覽量
