
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在編譯器設計中,列表和自組織列表是什麼?
列表
- 從概念上講,用線性記錄列表實現符號表的資料結構是最簡單和容易實現的,如下所示:

- 它可以使用單個數組來儲存名稱及其關聯的資訊。新名稱按遇到的順序插入到列表中。它可以從陣列的開頭到指標 AVAILABLE(指示陣列空部分的開頭)標記的位置檢索我們搜尋的名稱的相關資料。
- 當放置名稱時,可以在接下來的單詞中找到關聯的資料。如果我們在沒有識別名稱的情況下到達 available,則可能會出現使用未定義名稱的錯誤。
- 如果插入 n 個名稱和 m 個查詢,則總工作量為 c(n+m),其中 c 是表示新機器操作所需時間的常數。如果插入 n 個名稱和 m 個查詢,則總工作量為 c(n+m),其中 c 是表示新機器操作所需時間的常數。
關於列表資料結構的一些事實
- 新增新名稱所需的工作量與 n 成正比,其中符號表包含 n 個名稱。
- 在列表中搜索名稱的成本與 n/2 成正比。
- 要插入 n 個名稱和 m 個查詢,總工作量為
cn (n + m) 其中 c 為常數
優點
- 它用於最小化空間需求。
- 易於理解和實現。
缺點
- 它用於順序訪問
- 需要完成的工作量很大。
自組織列表
以犧牲少量額外空間為代價,可以使用一個技巧來節省大量搜尋符號表的時間。它可以向每個記錄新增一個 LINK 欄位,我們按 LINK 指示的順序搜尋列表。下圖顯示了一個包含四個名稱的符號表的示例。
FIRST 指示連結列表中第一個記錄的位置,每個 LINK 欄位表示列表中的下一個記錄。當引用名稱或首次建立其記錄時,可以透過移動指標將該名稱的記錄移動到列表的開頭。
這種方法用於減少列表組織中的搜尋時間。一個特殊的屬性連結被新增到名稱資訊中,允許列表具有動態特性,此特性有助於最大限度地減少空間浪費,並在一定程度上促進可重用性。
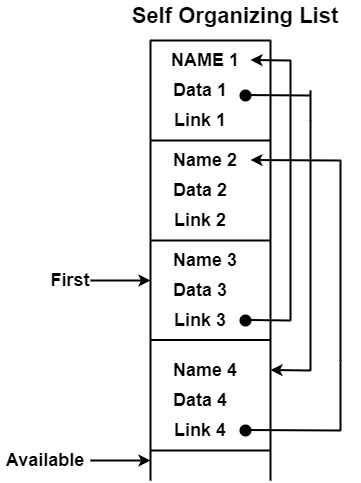
第一個指標指向符號表的開頭。
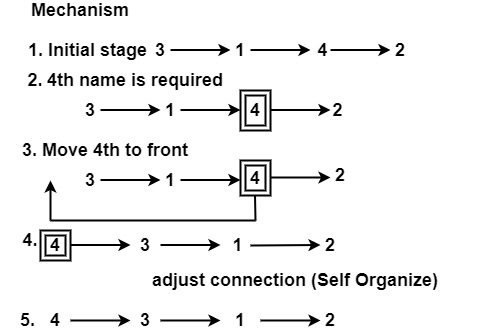
如果名稱按以下順序排列:
3 → 1 → 4 → 2
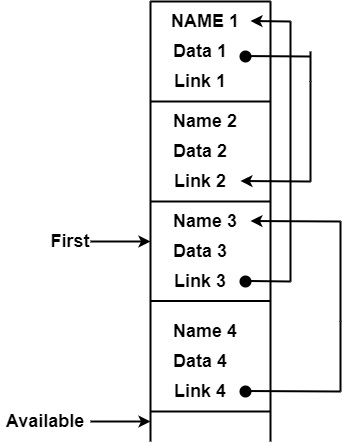
如果需要特定記錄,則需要將記錄移動到列表的開頭。
假設我們需要 4,那麼新的連線將是:
4 → 3 → 1 → 2
優點
- 它可以提高搜尋效率。
- 它可以在一定程度上提高可重用性。
缺點
- 維護如此多的連結和連線可能很困難。
- 它需要額外的空間。

更新於:2021年11月8日
瀏覽量 1K+

廣告