
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Pytorch Lightning 訓練神經網路
Pytorch Lightning是一個非常強大的框架,它簡化了訓練神經網路的過程。眾所周知,神經網路已成為解決機器學習相關問題的基本工具,然而訓練神經網路已成為一項必要但具有挑戰性的任務,需要仔細管理模型、資料和訓練迴圈,這就是我們使用 PyTorch Lightning 的原因。
在本文中,我們將探討什麼是 PyTorch Lightning,如何使用 PyTorch Lightning 訓練神經網路,它的優勢以及提高訓練過程的各種技術。
什麼是 PyTorch Lightning?
PyTorch Lightning 是一個使用者友好的 Python 庫,它簡化了神經網路的訓練。它旨在使深度學習對初學者和專家都更容易。PyTorch Lightning 提供了一個清晰且組織良好的框架來構建模型,而不是陷入複雜的程式碼中。
它負責處理繁瑣的任務,例如資料載入和訓練迴圈,因此我們可以專注於令人興奮的部分:設計網路架構和嘗試不同的技術。使用 PyTorch Lightning,您可以加快學習曲線並更快地取得進展。
PyTorch Lightning 用於訓練神經網路的優勢
PyTorch Lightning 為神經網路訓練提供了多項優勢 -
它透過將問題或關注點分解成單獨的模組(例如模型設計、資料載入和訓練迴圈)來鼓勵程式碼模組化。這種模組化方法使程式碼庫更容易除錯、理解和維護。
Pytorch lightning 自動執行許多常見任務,包括分散式訓練、梯度累積和日誌記錄。這使我們能夠專注於模型的主要元件,而不是實現問題。
使用 Pytorch Lightning 訓練神經網路的步驟
以下是使用 PyTorch Lightning 訓練神經網路的分步指南,PyTorch Lightning 是一個透過提供有用的抽象和處理單調任務來簡化訓練過程的框架。我們可以專注於建立模型和處理資料使用 PyTorch Lightning,而框架則處理訓練迴圈和其他複雜操作的複雜性 -
匯入我們將期望與神經網路和資料集一起使用的所有必要庫,例如 light 和 pytorch_lightning。
我們定義神經網路的結構。我們的模型包含幾個層,每一層在處理輸入資料和做出預測方面都有其特定的任務。'forward' 方法描述了資訊如何透過這些層移動。
定義模型後,我們繼續描述和執行訓練步驟。在準備過程中,模型獲取資料塊及其單獨的名稱。它使用這些批次來計算損失值並進行預測。此損失值解決了模型預測的準確程度。此外,我們記錄損失值以監視模型在學習過程中的進展。
為了提高模型的效能,我們將需要一個最佳化器。最佳化器幫助模型調整其內部引數以獲得更好的結果。
為了自動處理整個訓練過程,我們需要設定訓練器。我們還將指定訓練輪次的次數,這指的是模型在訓練期間將經歷的資料集的完整遍歷次數。
我們定義一個數據模組來處理資料集並將其設定為準備狀態。此模組處理堆疊資料集,在下面的程式示例中,使用了 MNIST 資料集,並將資料集轉換為模型可以處理的張量。
定義模型、資料模組和訓練器後,我們為每個模組建立例項。這些例項將在整個訓練過程中使用。
最後,我們準備開始訓練過程。我們呼叫訓練器的 'fit' 函式,該函式啟動訓練過程。訓練器為預定的輪次執行迴圈。
在每個輪次中,模型獲取資料批次,執行訓練步驟(進行預測、計算損失並最佳化引數),並重復此迴圈,直到整個資料集都已處理完畢。
示例
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as pl
# Define your neural network model
class NeuralNetwork(pl.LightningModule):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.model = nn.Sequential(
nn.Linear(784, 64),
nn.ReLU(),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.flatten(x)
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
# Create a PyTorch Lightning trainer
trainer = pl.Trainer(max_epochs=5)
# Create a PyTorch Lightning data module
class DataModule(pl.LightningDataModule):
def train_dataloader(self):
return DataLoader(MNIST(root="./data", train=True, transform=ToTensor(), download=True), batch_size=64)
# Create an instance of the data module
data_module = DataModule()
# Create an instance of the neural network model
model = NeuralNetwork()
# Train the model
trainer.fit(model, data_module)
輸出
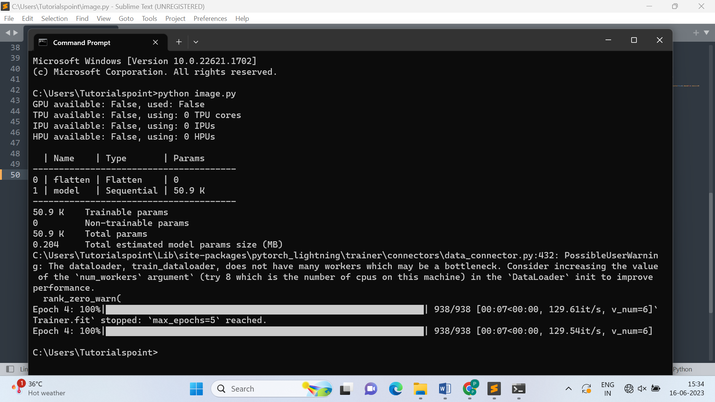
結論
總之,PyTorch Lightning 是一個強大的框架,它簡化了訓練神經網路的過程。它提供了一種結構化且組織良好的方法來管理資料、模型和訓練迴圈。透過抽象化 PyTorch 的複雜性,PyTorch Lightning 使研究人員和從業人員能夠專注於其模型的核心方面。憑藉其易用性和靈活性,PyTorch Lightning 是深度學習領域初學者和經驗豐富的從業人員的絕佳選擇。

427 次檢視
