
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP資料科學家應該瞭解的7大聚類演算法?
聚類演算法是一種機器學習演算法,可用於在資料集中查詢相似資料點的分組。這些演算法可用於各種應用,例如資料壓縮、異常檢測和主題建模。在某些情況下,聚類演算法可用於查詢資料集中可能並不立即明顯的隱藏模式或關係。透過將相似的資料點分組在一起,聚類演算法可以幫助簡化和理解大型和複雜的資料集。在這篇文章中,我們將仔細研究聚類演算法以及資料科學家應該熟悉的七大演算法。
什麼是聚類演算法?
聚類演算法是一種無監督的機器學習方法,用於在資料集中查詢相似資料點的分組。這些演算法不需要標記資料,而是尋找資料本身的模式和相關性。資料壓縮、異常檢測和主題建模只是使用聚類演算法的一些應用。
常見的聚類演算法包括 k 均值聚類、層次聚類和基於密度的聚類。這些演算法根據每個叢集內資料點的相似性將資料集劃分為組或叢集。聚類演算法的目的是找到最相關和最有價值的資料組,這有助於簡化和理解大型和複雜的資料集。
資料科學家應該瞭解的7大聚類演算法
資料科學家可以使用多種聚類方法,而使用哪種方法取決於手頭的特定問題。最流行的聚類演算法包括:
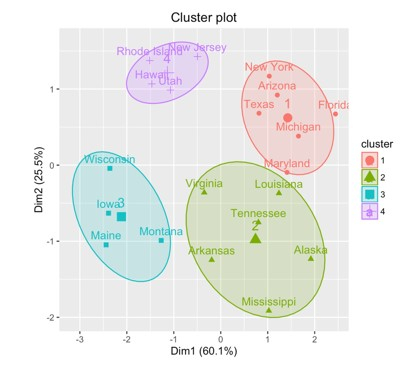
1. K均值聚類
K均值聚類是一種流行的聚類方法,它試圖將一組資料點劃分為預定的組數。它透過反覆將每個資料點分配到均值最近的叢集,然後根據分配給它的點更改每個叢集的均值來做到這一點。重複此過程,直到叢集收斂,然後演算法返回最終叢集。

K均值聚類的一個主要優點是它的簡單性和易於實現,這使其成為資料科學家中的流行選擇。它在計算上也很高效,使其適用於大型資料集。但是,K均值聚類的一個缺點是它假設叢集具有球形,這在現實世界的資料中並非總是如此。
2. 層次聚類
層次聚類是一種聚類分析方法,它試圖建立一個組的層次結構。在層次聚類中,叢集是按照從上到下的特定順序構建的。這意味著層次結構中較高層次的叢集更廣泛和包容,而較低層次的叢集更專業和排他。

層次聚類的基本原理是將相關的資料點分組到叢集中,然後分組到更大、更通用的叢集中,直到所有資料點都被叢集到層次結構頂部的單個叢集中。此方法使聚類演算法能夠捕獲資料的底層結構,並發現從原始資料中可能看不出的模式和相關性。
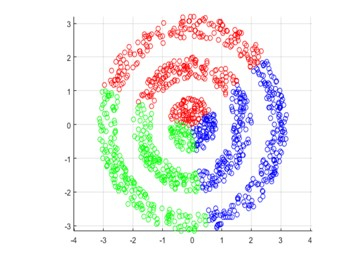
3. 基於密度的聚類
基於密度的聚類是一種聚類分析方法,它識別資料集中密度高的叢集。基於密度的聚類中的過程從選擇資料集中的一組點開始,這些點被大量其他點包圍。

這些點被認為是密集區域的一部分,然後演算法將嘗試擴充套件此區域以包含叢集的所有點。此方法使演算法能夠找到任何形狀的叢集,這使其非常適合沒有明顯和可識別結構的資料集。DBSCAN 和 HDBSCAN 是基於密度的聚類演算法的兩個例子。
4. 模糊聚類
模糊聚類,也稱為軟聚類,是一種聚類分析技術,它允許資料點屬於多個叢集。在模糊聚類中,每個資料點都被分配一個成員資格值,該值反映了它屬於每個叢集的程度。這意味著資料點可以部分分配給多個叢集,而不是像在傳統的(硬)聚類方法中那樣完全分配給一個叢集。
當資料點不明顯屬於其中一個叢集或叢集本身沒有明確定義時,這很有用。模糊 C 均值 (FCM) 和 Gustafson-Kessel (GK) 演算法是模糊聚類演算法的兩個例子。
5. 基於模型的聚類
基於模型的聚類是一種聚類分析技術,它涉及將統計模型擬合到資料以發現叢集。基於模型的聚類中的過程首先指定資料的機率模型,例如高斯分佈的混合。
然後,演算法使用最佳化技術來選擇最適合資料的模型引數集。此方法使演算法能夠捕獲資料的底層結構,並發現從原始資料中可能看不出的叢集。期望最大化 (EM) 演算法和貝葉斯高斯混合模型是基於模型的聚類演算法的兩個例子。
6. EM 聚類
期望最大化 (EM) 演算法,通常稱為 EM 聚類,是一種聚類分析方法,它使用機率方法來發現資料集中存在的叢集。EM 演算法是一種迭代方法,它首先猜測表示資料的統計模型的引數。然後使用這些引數來計算每個資料點屬於每個叢集的機率。這被稱為期望步驟。
然後,演算法使用這些機率來更新模型引數,這是一個稱為最大化的過程。重複此過程,直到模型引數收斂到穩定的解決方案。EM 聚類特別適用於具有複雜底層結構的資料集,對於這些資料集,傳統的聚類方法可能無法很好地工作。
7. DBSCAN
DBSCAN(基於密度的應用空間聚類噪聲)是一種流行的基於密度的聚類技術。它是一種聚類方法,它識別資料集中密度高的叢集。DBSCAN 透過查詢資料集中被大量其他點包圍的點來工作。
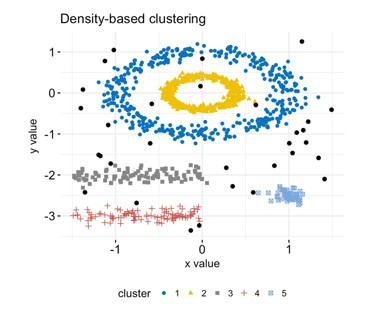
這些點被認為是密集區域的一部分,然後演算法將嘗試擴充套件此區域以包含叢集的所有點。此方法使演算法能夠找到任何形狀的叢集,這使其非常適合沒有明確定義結構的資料集。DBSCAN 演算法由於其可擴充套件性和效率而在許多不同的應用中使用。
結論
總而言之,聚類演算法是資料科學家查詢資料集中模式和關係的有效工具。這些方法適用於各種資料和聚類應用,並使用各種策略將可比資料點分組到叢集中。最佳聚類方法的選擇將取決於資料集的個體特徵和研究的目標。有幾種型別的聚類演算法,每種演算法都有其獨特的優勢和侷限性。作為資料科學家,全面瞭解各種聚類演算法及其功能對於選擇適合您研究的最佳聚類方法至關重要。

212 次瀏覽
