
 資料結構
資料結構 網路
網路 RDBMS
RDBMS 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 語言程式設計
C 語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP關係型資料庫管理系統 (RDBMS)
關係資料庫設計 (RDD) 模型將資訊和資料組織成一組包含行和列的表。關係/表的每一行表示一條記錄,每一列表示資料的某個屬性。結構化查詢語言 (SQL) 用於操作關係資料庫。關係資料庫的設計由四個階段組成,其中資料被建模成一組相關的表。這些階段包括:
- 定義關係/屬性
- 定義主鍵
- 定義關係
- 規範化
關係資料庫在組織資料和執行事務方面與其他資料庫不同。在 RDD 中,資料被組織成表,所有型別的資料訪問都透過受控事務執行。關係資料庫設計滿足資料庫設計所需的 ACID(原子性、一致性、完整性和永續性)屬性。關係資料庫設計要求在應用程式中使用資料庫伺服器來處理資料管理問題。

關係資料庫設計過程
資料庫設計更像是一門藝術而不是科學,因為您必須做出許多決策。資料庫通常會被定製以適應特定的應用程式。沒有兩個定製的應用程式是相同的,因此,也沒有兩個資料庫是相同的。在做出這些設計決策時,會提供一些指導原則(通常是關於“不要做什麼”而不是“做什麼”),但最終的選擇權在於設計者。
步驟 1 - 定義資料庫的目的(需求分析)
- 收集需求並定義資料庫的目標。
- 草擬示例輸入表單、查詢和報表通常會有所幫助。
步驟 2 - 收集資料,組織成表並指定主鍵
- 確定資料庫的目的後,收集需要儲存在資料庫中的資料。將資料劃分為基於主題的表。
- 選擇一列(或幾列)作為所謂的“主鍵”,它唯一地標識每一行。
步驟 3 - 建立表之間的關係
一個由獨立且不相關的表組成的資料庫幾乎沒有用處(您可以考慮使用電子表格)。關係資料庫的強大之處在於可以在表之間定義關係。設計關係資料庫最關鍵的方面是識別表之間的關係。關係型別包括:
- 一對多
- 多對多
- 一對一
一對多
在“課程花名冊”資料庫中,一位老師可以教授零個或多個課程,而一個課程由一位(且僅一位)老師教授。在“公司”資料庫中,一位經理可以管理零個或多個員工,而一位員工由一位(且僅一位)經理管理。在“產品銷售”資料庫中,一位客戶可以下多個訂單;而一個訂單是由一位特定客戶下的。這種關係被稱為一對多。
一對多關係不能在一個表中表示。例如,在“課程花名冊”資料庫中,我們可以從一個名為 Teachers 的表開始,其中儲存有關教師的資訊(例如姓名、辦公室、電話和電子郵件)。為了儲存每位教師教授的課程,我們可以建立列 class1、class2、class3,但立即面臨一個問題,即建立多少列。另一方面,如果我們從一個名為 Classes 的表開始,其中儲存有關課程的資訊,我們可以建立其他列來儲存有關(一個)教師的資訊(例如姓名、辦公室、電話和電子郵件)。但是,由於一位教師可以教授許多課程,因此其資料將在 Classes 表的許多行中重複。
為了支援一對多關係,我們需要設計兩個表:例如,一個 Classes 表來儲存有關課程的資訊,classID 作為主鍵;以及一個 Teachers 表來儲存有關教師的資訊,teacherID 作為主鍵。然後,我們可以透過在 Classes 表(“多”端或子表)中儲存 Teacher 表(“一”端或父表)的主鍵(即 teacherID)來建立一對多關係,如下所示。
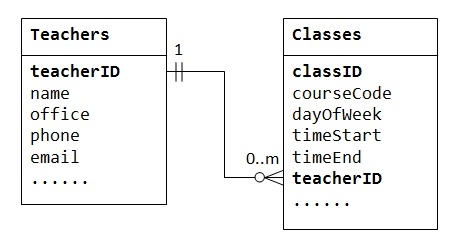 子表 Classes 中的列 teacherID 被稱為外部索引鍵。子表的外部索引鍵是父表的主鍵,用於引用父表。
子表 Classes 中的列 teacherID 被稱為外部索引鍵。子表的外部索引鍵是父表的主鍵,用於引用父表。
多對多
在“產品銷售”資料庫中,客戶的訂單可能包含一個或多個產品;並且一個產品可以出現在多個訂單中。在“書店”資料庫中,一本書由一個或多個作者撰寫;而一個作者可以撰寫零個或多個書籍。這種關係被稱為多對多。
讓我們以“產品銷售”資料庫為例。我們從兩個表開始:Products 和 Orders。Products 表包含有關產品的資訊(例如名稱、描述和庫存數量),productID 作為其主鍵。Orders 表包含客戶的訂單(customerID、dateOrdered、dateRequired 和狀態)。同樣,我們不能在 Orders 表中儲存訂購的商品,因為我們不知道為商品保留多少列。我們也不能在 Products 表中儲存訂單資訊。
為了支援多對多關係,我們需要建立一個第三個表(稱為連線表),例如 OrderDetails(或 OrderLines),其中每一行表示特定訂單的商品。對於 OrderDetails 表,主鍵包含兩列:orderID 和 productID,它們唯一地標識每一行。OrderDetails 表中的列 orderID 和 productID 用於引用 Orders 和 Products 表,因此它們也是 OrderDetails 表中的外部索引鍵。
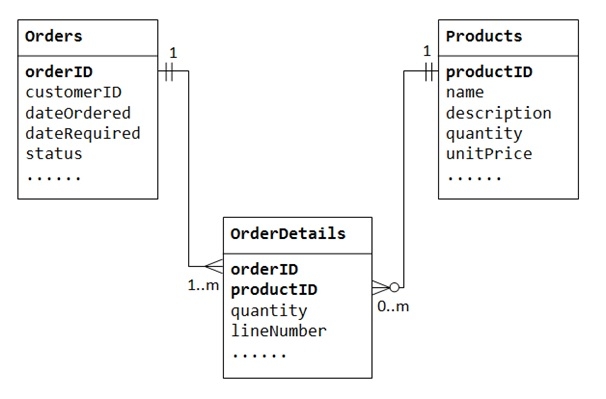
實際上,多對多關係是透過引入連線表實現為兩個一對多關係。
一個訂單在 OrderDetails 中有多個商品。OrderDetails 商品屬於一個特定訂單。
一個產品可能出現在多個 OrderDetails 中。每個 OrderDetails 商品指定了一個產品。
一對一
在“產品銷售”資料庫中,一個產品可能有一些可選的補充資訊,例如影像、更多描述和評論。將它們保留在 Products 表中會導致許多空單元格(在沒有這些可選資料的記錄中)。此外,這些大型資料可能會降低資料庫的效能。
相反,我們可以建立另一個表(例如 ProductDetails、ProductLines 或 ProductExtras)來儲存可選資料。僅為具有可選資料的那些產品建立記錄。這兩個表 Products 和 ProductDetails 表現出一對一的關係。也就是說,對於父表中的每一行,子表中最多隻有一行(可能為零)。相同的列 productID 應被用作兩個表的主鍵。
一些資料庫限制了可以在表中建立的列數。您可以使用一對一關係將資料拆分為兩個表。一對一關係也可用於將某些敏感資料儲存在安全表中,而將非敏感資料儲存在主表中。

列資料型別
您需要為每一列選擇合適的資料型別。常用的資料型別包括整數、浮點數、字串(或文字)、日期/時間、二進位制、集合(如列舉和集合)。
步驟 4 - 細化和規範化設計
例如,
- 新增更多列,
- 使用一對一關係為可選資料建立新表,
- 將一個大表拆分為兩個較小的表,
- 其他方法。
規範化
應用所謂的規範化規則來檢查您的資料庫結構是否正確且最優。
第一正規化 (1NF):如果每個單元格包含單個值,而不是值列表,則該表為 1NF。此屬性稱為原子性。1NF 還禁止重複的列組,例如 item1、item2、itemN。相反,您應該使用一對多關係建立另一個表。
第二正規化 (2NF) − 當一個表滿足第一正規化,並且每個非鍵列都完全依賴於主鍵時,該表就處於第二正規化。此外,如果主鍵由多個列組成,則每個非鍵列都應依賴於整個主鍵,而不是其中的一部分。
例如,OrderDetails 表的主鍵由 orderID 和 productID 組成。如果 unitPrice 僅依賴於 productID,則它不應該儲存在 OrderDetails 表中(而應該儲存在 Products 表中)。另一方面,如果單價依賴於產品以及特定的訂單,則它應該儲存在 OrderDetails 表中。
第三正規化 (3NF) − 當一個表滿足第二正規化,並且非鍵列之間相互獨立時,該表就處於第三正規化。換句話說,非鍵列僅依賴於主鍵,且僅依賴於主鍵,不依賴於其他任何東西。例如,假設我們有一個 Products 表,其列包括 productID(主鍵)、name 和 unitPrice。如果 discountRate 也依賴於 unitPrice(不是主鍵的一部分),則 discountRate 不應屬於 Products 表。
更高正規化:第三正規化存在一些不足,這導致了更高正規化的出現,例如 Boyce/Codd 正規化、第四正規化 (4NF) 和第五正規化 (5NF),這些內容在本教程中不作介紹。
有時,出於效能原因(例如,在 Orders 表中建立一個名為 totalPrice 的列,該列可以從 orderDetails 記錄中推匯出來),或者由於終端使用者的請求,您可能決定打破某些規範化規則;請確保您充分了解這一點,並開發相應的程式設計邏輯來處理它,以及正確記錄您的決策。
完整性規則
您還應該應用完整性規則來檢查設計的完整性 −
1. 實體完整性規則 − 主鍵不能包含空值。否則,它無法唯一地識別行。對於由多個列組成的組合鍵,任何列都不能包含空值。大多數 RDBMS 會檢查並執行此規則。
2. 參照完整性規則 − 每個外部索引鍵值必須與被引用表(或父表)中的主鍵值匹配。
只有當父表中存在該值時,您才能在子表中插入包含外部索引鍵的行。
如果父表中鍵的值發生更改(例如,行更新或刪除),則必須相應地處理子表中所有具有此外部索引鍵的行。您可以 (a) 禁止更改;(b) 在子表中級聯更改(或刪除記錄);(c) 將子表中的鍵值設定為 NULL。
大多數 RDBMS 可以設定為以指定的方式執行檢查並確保參照完整性。
3. 業務邏輯完整性 − 除了以上兩個通用完整性規則外,還可能存在與業務邏輯相關的完整性(驗證),例如,郵政編碼應為 5 位數字,並在特定範圍內,送貨日期和時間應在營業時間內;訂購數量應等於或小於庫存數量等。這些可以透過驗證規則(針對特定列)或程式設計邏輯來執行。
列索引
您可以在選定的列上建立索引以方便資料搜尋和檢索。索引是一個結構化檔案,可以加快 SELECT 查詢的資料訪問速度,但可能會降低 INSERT、UPDATE 和 DELETE 的速度。如果沒有索引結構,要處理具有匹配條件的 SELECT 查詢(例如,SELECT * FROM Customers WHERE name='Tan Ah Teck'),資料庫引擎需要比較表中的每條記錄。一個專門的索引(例如,BTREE 結構)可以在不比較每條記錄的情況下找到記錄。但是,每當記錄發生更改時,都需要重建索引,這會導致與使用索引相關的開銷。
索引可以定義在單個列上、一組列上(稱為連線索引)或列的一部分上(例如,VARCHAR(100) 的前 10 個字元)(稱為部分索引)。您可以在一個表中構建多個索引。例如,如果您經常使用 customerName 或 phone number 搜尋客戶,則可以透過在 customerName 列和 phoneNumber 列上構建索引來加快搜索速度。大多數 RDBMS 會自動為主鍵構建索引。

17K+ 次瀏覽
