
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用正則表示式統計Python程式中大寫字母、小寫字母、特殊字元和數字字元個數的程式
正則表示式,通常簡稱為re或Regex,是用於操作和搜尋文字模式的強大工具。在Python中,正則表示式是使用re模組實現的。正則表示式是一系列字元,用於定義搜尋模式。該模式用於匹配和操作文字字串,這對於資料清洗、解析和驗證等任務非常有用。
為了使用正則表示式(regex)統計字串中大寫字母、小寫字母、特殊字元和數字字元的個數,我們可以使用特定的模式來匹配和統計所需的字元。
以下是使用正則表示式統計大寫字母、小寫字母、特殊字元和數字字元個數的模式及其解釋:
大寫字母:
模式:[A-Z]
解釋:模式[A-Z]匹配從A到Z的任何大寫字母。連字元-指定字元範圍。因此,此模式匹配輸入字串中的任何大寫字母。
小寫字母:
模式:[a-z]
解釋:模式[a-z]匹配從a到z的任何小寫字母。與大寫字母類似,此模式捕獲輸入字串中的任何小寫字母。
特殊字元:
模式:[A-Za-z0-9]
解釋:模式[^A-Za-z0-9]匹配任何不是大寫字母、小寫字母或數字的字元。方括號[]內的脫字元^表示否定。因此,此模式匹配不在A-Z、a-z或0-9範圍內的任何特殊字元。
數字:
模式:[0-9]
解釋:該模式匹配從0到9的任何數字。
為了統計每個類別的出現次數,我們可以使用Python中re模組的re.findall()函式。此函式搜尋輸入字串中模式的所有不重疊的出現,並將其作為列表返回。生成的列表的長度給出了出現次數。
輸入輸出場景
讓我們探索一些輸入輸出場景,以統計給定字串中大寫字母、小寫字母、特殊字元和數字字元的個數。
場景1:
Input string: Hello World! Output: Uppercase letters: 2 Lowercase letters: 8 Special characters: 1 Numeric values: 0
輸入字串“Hello World!”包含2個大寫字母(H和W)、8個小寫字母(e、l、l、o、o、r、l、d)、1個特殊字元(!)和0個數字。
場景2:
Input string: @#Hello1234#@ Output: Uppercase letters: 1 Lowercase letters: 4 Special characters: 4 Numeric values: 4
輸入字串“@#Hello1234#@”包含1個大寫字母(H)、4個小寫字母(e、l、l、o)、4個特殊字元(@、#、#、@)和4個數字(1、2、3、4)。
示例
讓我們舉個例子來統計給定字串中大寫字母、小寫字母、特殊字元和數字字元的個數。
import re
def count_characters(input_string):
uppercase_count = len(re.findall(r'[A-Z]', input_string))
lowercase_count = len(re.findall(r'[a-z]', input_string))
special_count = len(re.findall(r'[^A-Za-z0-9]', input_string))
numeric_count = len(re.findall(r'[0-9]', input_string))
return uppercase_count, lowercase_count, special_count, numeric_count
# define the input string
input_str = 'Tutor1als!p0int'
upper, lower, special, numeric = count_characters(input_str)
print("Uppercase letters:", upper)
print("Lowercase letters:", lower)
print("Special characters:", special)
print("Numeric values:", numeric)
輸出
Uppercase letters: 1 Lowercase letters: 11 Special characters: 1 Numeric values: 2
示例
在這個例子中,我們將統計文字檔案中大寫字母、小寫字母、特殊字元和數字字元的個數。以下是文字檔案中存在的資料:
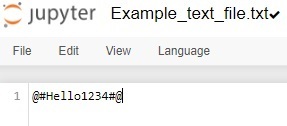
import re
def count_characters(filename):
with open(filename, 'r') as file:
for line in file:
uppercase_count = len(re.findall(r'[A-Z]', line))
lowercase_count = len(re.findall(r'[a-z]', line))
special_count = len(re.findall(r'[^A-Za-z0-9]', line))
numeric_count = len(re.findall(r'[0-9]', line))
return uppercase_count, lowercase_count, special_count, numeric_count
# Provide the path of the text file
file = 'Example_text_file.txt'
# Call the function to count Uppercase, Lowercase, special character and numeric values
upper, lower, special, numeric = count_characters(file)
print("Uppercase letters:", upper)
print("Lowercase letters:", lower)
print("Special characters:", special)
print("Numeric values:", numeric)
輸出
Uppercase letters: 1 Lowercase letters: 4 Special characters: 4 Numeric values: 4

626 次檢視
