
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用列表中的列在 PySpark 中按多列分割槽
你是否曾經想過資料處理公司如何有效地管理海量資料集?分割槽是其中一種關鍵方法。本文將探討 PySpark 中的分割槽概念,重點介紹如何使用列表按多列進行分割槽。我們將逐步分解整個過程,即使是初學者也能理解。
引言
在當今大資料時代,高效處理和管理大型資料集至關重要。Apache Spark,特別是 PySpark(Spark 的 Python API),是管理此類任務的有效解決方案。“分割槽”是最大化 PySpark 查詢速度和資料管理的最佳策略之一。本文將介紹 PySpark 中的分割槽概念,重點介紹如何按多列(特別是列的列表)進行分割槽。什麼是分割槽?
分割槽過程是指將大型資料集分解成更小、更容易管理的片段或“分割槽”。PySpark 現在可以同時處理多個較小的檔案,從而避免處理單個大型檔案,節省處理時間。這就像把一個大披薩切成片,這樣每個人都能更快地吃!假設您正在處理一個包含全年來自不同地區多個商店的銷售資料的資料集。如果您正在查詢來自單個儲存的資訊,分割槽使您可以更快、更容易地僅獲取所需的資料。
為什麼要按多列分割槽?
按多列分割槽意味著根據多個列劃分資料集。例如,如果您有一個包含“班級”和“組別”列的學生資料集,您可以同時按“班級”和“組別”對資料進行分割槽。這有助於更好地組織資料,並加快某些操作的處理速度。術語解釋
在深入研究程式碼之前,讓我們定義一些重要的術語- PySpark:Apache Spark 的 Python API,允許您使用 Spark 的分散式計算功能。
- 分割槽:資料集的一個小子集,物理上分離到磁碟上的較小檔案中,以提高讀寫效能。
- DataFrame:PySpark 中一種二維的、類似表格的結構,可以容納帶有行和列的資料,類似於電子表格或 SQL 表。
- 列:在表(或 DataFrame)中,列表示特定的資料欄位,例如“年齡”或“位置”。
- 列表:以特定順序儲存元素的集合。在 Python 中,列表可以容納數字或字串等值,靈活且易於使用。
為什麼在 PySpark 中使用分割槽?
分割槽有助於以下方面:- 效能提升:當資料被分割槽後,PySpark 可以跨多個節點並行化資料的讀取和處理,從而加快速度。
- 高效的資料檢索:PySpark 只會掃描所需的分割槽,從而節省 I/O 操作,而不是掃描整個資料集。
- 可擴充套件性:當任務在分割槽之間拆分時,管理大型資料集變得更容易。
分步指南:在 PySpark 中按多列分割槽
本節將向您展示如何使用 PySpark 和公共資料集按多列對資料集進行分割槽。在本例中,我們將使用著名的“鳶尾花”資料集,其中包含有關幾種花卉物種及其尺寸的詳細資訊。步驟 1:安裝所需的庫
pip install pyspark pandas matplotlib ipywidgets
步驟 2:載入資料集
我們將使用鳶尾花資料集,該資料集可從 UCI 機器學習儲存庫公開獲取。我們可以使用 pandas 直接從 URL 載入它。import pandas as pd
# Load the Iris dataset from a public URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_df = pd.read_csv(url, names=columns)
# Display the first few rows of the dataset
iris_df.head()
步驟 3:設定 PySpark
接下來,我們需要設定 PySpark 並將我們的 pandas DataFrame 轉換為 PySpark DataFrame。from pyspark.sql import SparkSession
# Initialize a Spark session
spark = SparkSession.builder.appName("PartitioningExample").getOrCreate()
# Convert pandas DataFrame to PySpark DataFrame
spark_df = spark.createDataFrame(iris_df)
# Show first few rows of the PySpark DataFrame
spark_df.show(5)
步驟 4:按多列分割槽
這裡的目標是按兩個列(species 和 sepal_length)對資料進行分割槽。讓我們將它們定義為我們的分割槽列。# Specify the columns to partition by
partition_columns = ["species", "sepal_length"]
# Partition the data and save it as Parquet files
output_path = "output/partitioned_iris"
spark_df.write.partitionBy(partition_columns).parquet(output_path)
步驟 5:資料視覺化
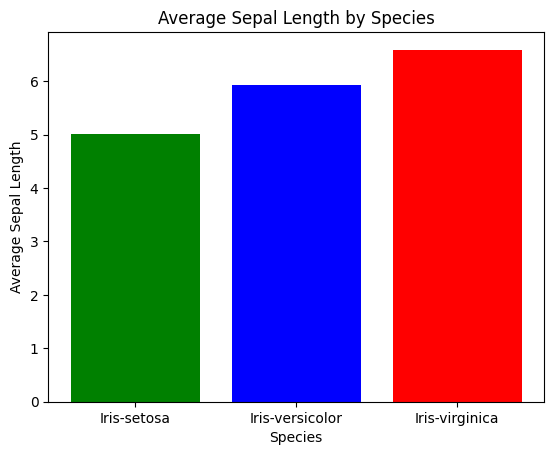
現在,讓我們視覺化分割槽的工作原理。我們將繪製不同物種中 sepal_length 的分佈,以瞭解分割槽如何幫助我們。import matplotlib.pyplot as plt
# Extract relevant data for plotting
iris_grouped = iris_df.groupby('species')['sepal_length'].mean().reset_index()
# Plotting
plt.bar(iris_grouped['species'], iris_grouped['sepal_length'], color=['green', 'blue', 'red'])
plt.xlabel('Species')
plt.ylabel('Average Sepal Length')
plt.title('Average Sepal Length by Species')
plt.show()
輸出
分割槽最佳實踐
- 明智地選擇列:選擇分割槽列時,請確保每列中唯一值的個數相對較少。如果按其進行分割槽的列具有過多的唯一值,則會產生大量的小檔案,這可能會降低效能。
- 監控分割槽大小:目標是使分割槽既不太大也不太小。理想情況下,每個分割槽的最佳大小應在 100MB 到 1GB 之間。
- 避免過度分割槽:過度分割槽會導致產生太多的小檔案,從而增加了在分散式系統中處理這些檔案的成本。
常見問題解答
問:為什麼分割槽對大資料很重要?
答:分割槽透過將大型資料集劃分為更小、更容易管理的塊來提高可擴充套件性和效能。問:我可以按多於兩列分割槽嗎?
答:當然!您可以根據需要使用任意數量的列進行分割槽,但是避免過度分割槽,因為這可能會導致效率低下。問:所有資料集都需要分割槽嗎?
答:不需要,當您經常需要對特定資料組執行操作時,分割槽對於大型資料集很有幫助。結論
分割槽是一種強大的方法,可以提高 PySpark 中大資料處理的效率。透過學習如何按多列(特別是使用列表)進行分割槽,您可以顯著提高資料操作的效能。只需在選擇分割槽列時小心,並避免建立過多的小檔案即可。無論處理的資料集大小如何,瞭解如何分割槽資料在大資料分析領域都是至關重要的。**祝您程式設計愉快!**更新於:2024年9月10日
60 次瀏覽

廣告