
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPHive動態分割槽概述
Hive是由Facebook開發的,用於分析和MapReduce作業。它可以讀取、寫入和管理大型資料集。Hive可以替代傳統的資料庫操作。Hive使用索引來提高查詢效率,並且可以處理儲存在Hadoop生態系統中的壓縮資料。
在本文中,我們將討論Hive中的動態分割槽及其操作。
Apache Hive
Apache Hive是一個數據倉庫系統,用於對結構化資料執行操作。它廣泛用於分析和MapReduce作業。Apache Hive提供讀取、寫入和管理大型資料集的功能。Hive的關鍵特性之一是其對資料進行分割槽的能力。在本文中,我們將概述Hive中的動態分割槽。
Hive中的分割槽
分割槽是將大型資料集劃分為更小、更易於管理的部分的過程。Hive中有兩種分割槽型別:靜態分割槽和動態分割槽。
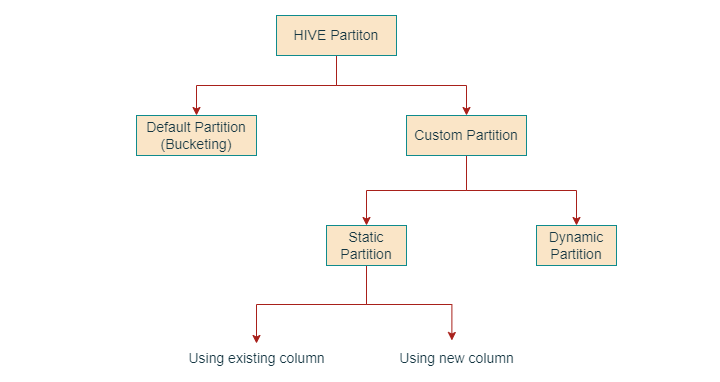
靜態分割槽
在將資料插入分割槽表時,它會指定每個記錄的分割槽鍵和值。這種方法用於分割槽數量較少的情況。
動態分割槽
它具有更靈活的方法。它根據插入的資料確定分割槽鍵和值。對於具有大量分割槽的大型資料集,它是更好的選擇。
動態分割槽的特性
它有很多特性,這些特性使其成為處理儲存在分散式儲存中的大量資料的理想選擇。以下是動態分割槽的一些特性:
能夠處理大型資料集
動態分割槽是從非分割槽表載入資料的策略方法。它處理儲存在分散式儲存中的大型資料集。
支援外部表和管理表
可以在Hive的外部表和管理表上執行動態分割槽。
不需要WHERE子句
與靜態分割槽不同,動態分割槽不需要WHERE子句來指定分割槽鍵和值。
能夠處理結構未知的表
動態分割槽可以用於對錶進行分割槽,而無需預先知道列的數量。
動態分割槽的操作
以下是執行Hive動態分割槽操作的步驟:
步驟1 - 建立要執行操作的資料庫並選擇它。
步驟2 - 使用以下命令啟用動態分割槽
hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition.mode=nonstrict;
步驟3 - 建立一個表來儲存資料。
步驟4 - 將資料載入到表中。
步驟5 - 使用`partitioned by`子句建立一個分割槽表。
步驟6 - 將資料載入到分割槽表中。
步驟7 - 執行查詢操作。
步驟8 - 要刪除動態分割槽列,請使用以下命令
hive> alter table partitioned_table drop partition (partition_col = 'value');
請務必將`partition_col`和`value`替換為相應的列名和值。
結論
動態分割槽是Hive的一個特性,它高效且靈活地處理儲存在分散式儲存中的大型資料集。它可以成為分析和MapReduce作業的絕佳選擇。執行動態分割槽操作的步驟相對簡單易懂。使用者可以充分利用Hive中的動態分割槽,從而提高資料管理和分析能力。Hive是大資料工具,憑藉動態分割槽等特性,它變得更加多功能和寶貴。

523 次瀏覽
