
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Python 中的 lxml 實現網頁抓取?
網頁抓取不僅讓資料科學愛好者興奮不已,也讓希望深入研究網站的學生或學習者感到興奮。Python 提供了許多網頁抓取庫,包括:
Scrapy
Urllib
BeautifulSoup
Selenium
Python Requests
LXML
我們將討論 Python 的 lxml 庫,用於從網頁抓取資料。該庫建立在用 C 編寫的 libxml2 XML 解析庫之上,這使其比 BeautifulSoup 更快,但也使其在某些計算機(特別是 Windows)上更難安裝。
安裝和匯入 lxml
可以使用 pip 從命令列安裝 lxml:
pip install lxml
或者
conda install -c anaconda lxml
lxml 安裝完成後,匯入 html 模組,該模組解析來自 lxml 的 HTML。
>>> from lxml import html
檢索要抓取的頁面原始碼 - 我們有兩個選擇,我們可以使用 python requests 庫或 urllib,並使用它來建立一個包含頁面整個 HTML 的 lxml HTML 元素物件。我們將使用 requests 庫下載頁面的 HTML 內容。
要安裝 python requests,只需在您選擇的終端中執行以下簡單命令:
$ pipenv install requests
從雅虎財經抓取資料
假設我們想從 google.finance 或 yahoo.finance 抓取股票/股權資料。以下是雅虎財經中微軟公司的螢幕截圖:

因此,從上面(https://finance.yahoo.com/quote/msft),我們將提取所有可見的股票欄位,例如:
前收盤價、開盤價、買價、賣價、當日區間、52 周區間、成交量等。
以下是使用 python lxml 模組完成此操作的程式碼:
lxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4)要執行上述程式碼,只需在您的命令終端中鍵入以下內容:
c:\Python\Python361>python lxml_scrape3.py MSFT
執行 lxml_scrap3.py 後,您將看到在當前工作目錄中建立了一個 .json 檔案,其名稱類似於“stockName-summary.json”,因為我嘗試從雅虎財經中提取 msft(微軟)欄位,因此建立了一個名為“msft-summary.json”的檔案。
以下是生成的輸出的螢幕截圖:
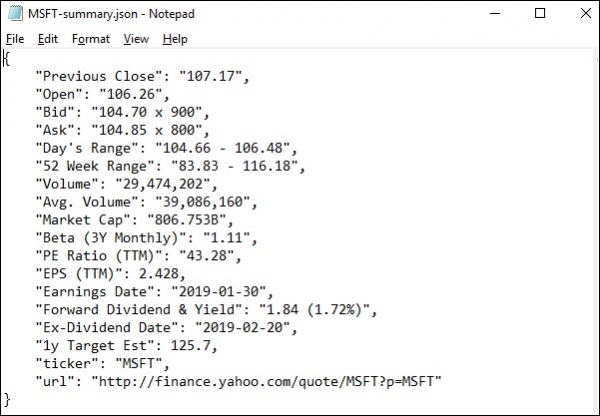
因此,我們已成功使用 lxml 和 requests 從雅虎財經的微軟頁面抓取所有所需資料,然後將資料儲存到檔案中,稍後可用於共享或分析微軟股票的價格走勢。

523 次檢視
