
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在計算機體系結構中消除負載使用延遲?
處理器的流水線佈局會影響負載使用延遲。下圖顯示了傳統的 RISC、MIPS 和 CISC 流水線佈局以及相關的負載使用延遲。
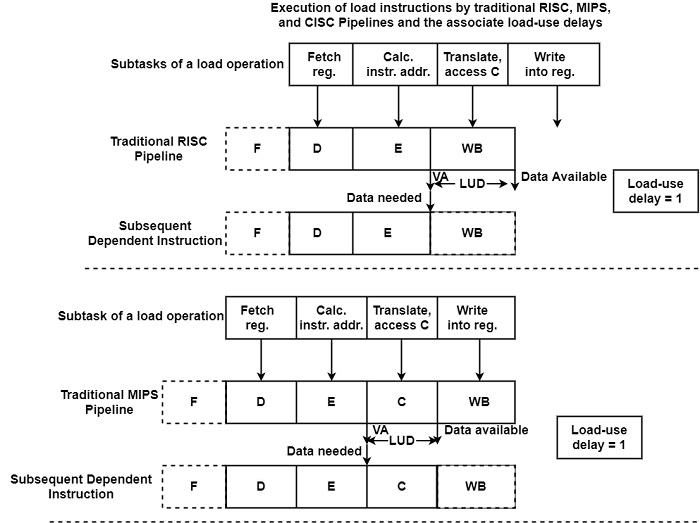
對於傳統的四階段 RISC 流水線,首先,在 D 階段訪問暫存器以獲取地址計算的組成部分,例如指定基址或索引暫存器的內容。接下來,在 E 階段,使用 FX 加法器計算有效(虛擬)地址。在本週期結束時,虛擬地址可以傳送到 MMU 和/或快取。假設使用高效能快取,資料將在下一個流水線週期結束時可用,從而導致一個週期的負載延遲。
對於傳統的 MIPS 流水線,虛擬地址再次在 E 階段結束時發出。再次假設單週期快取延遲,請求的資料將在 C 週期結束時從快取到達。因此,傳統的 MIPS 流水線也具有一個週期的負載使用延遲。
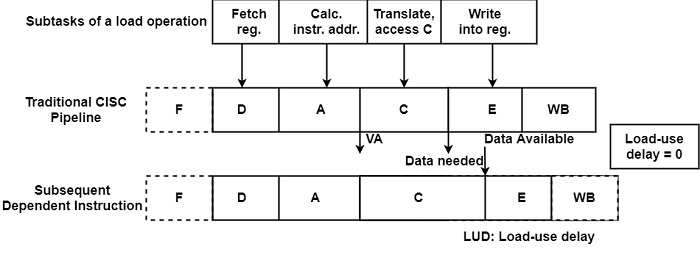
另一方面,傳統的 CISC 流水線設計用於處理暫存器-記憶體指令。因此,它的佈局使得即使在同一指令的 E 階段也可以使用引用的記憶體資料,如下圖所示。
因此,佈局根本不會導致負載使用延遲。但是,由於流水線階段數量較多,因此並行執行的指令更多,因此與四階段或五階段流水線相比,可以預期出現更多相關的指令。這一事實可能會不利地影響效能。
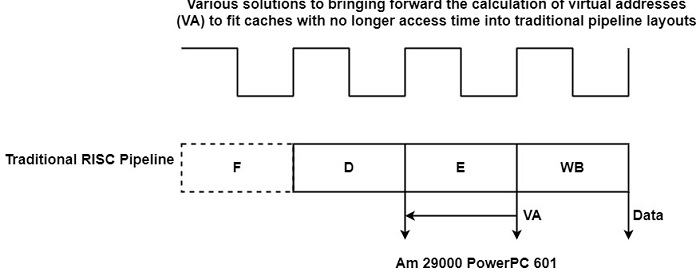
它可以假設一個高效能快取,能夠在一個週期內訪問資料,包括地址轉換和假設快取命中。對於較慢的快取,如果未採取任何特殊措施,則負載使用延遲會更長。接下來,我們將展示減少較慢快取負載使用延遲的技術。透過將地址計算過程提前半個或整個流水線週期來匹配較慢的快取到流水線佈局中,如下圖所示。
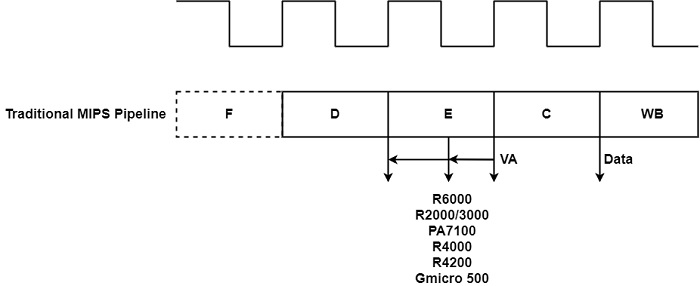
例如,在 R2000 和 R3000 處理器中,地址計算發生在 E 週期的前半部分。高效能 HP 7100 也同樣適用。該處理器是獨特的,因為它使用片外快取,這解釋了需要轉發地址計算子任務的原因。
一些處理器,例如 Am 29000 或 R6000,甚至將地址計算移到解碼 (D) 階段的最後階段。

263 次檢視
