
 資料結構
資料結構 網路
網路 關係資料庫管理系統
關係資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Selenium Python 定位元素?
隨著技術的不斷變化,為了在網路上呈現內容,經常需要重新設計和重構網頁或網站的內容。Selenium 與 Python 的結合是一個很好的組合,有助於從網頁中提取所需的內容。Selenium 是一種免費的開源自動化工具,用於在多個平臺上評估 Web 應用程式。Selenium 測試指令碼可以用多種計算機語言編寫,例如 Java、C#、Python、NodeJS、PHP、Perl 等。在這篇 Python Selenium 文章中,透過兩個不同的示例,給出了使用 Selenium 定位網頁元素的方法。在這兩個示例中,都使用了新聞網站來提取內容。
定位要提取的元素 -
開啟要從中提取內容的網站。現在按下滑鼠右鍵並開啟檢查視窗。突出顯示網頁上的元素或部分,並在檢查視窗中檢視其 HTML 設計規範。使用這些規範來定位元素。
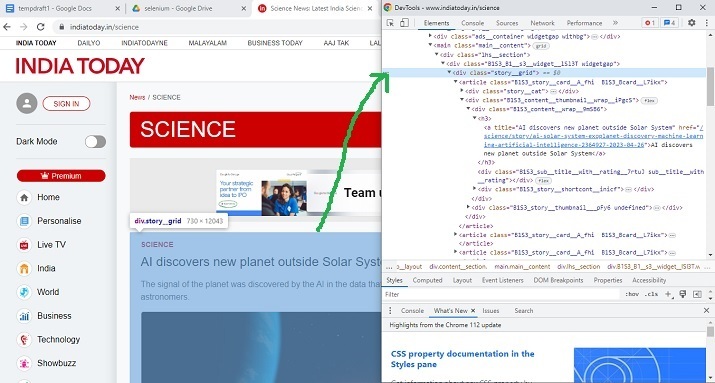
示例 1:使用 Selenium 和 Python 定位具有特定類名的 div 元素
演算法
步驟 1 - 首先下載與 Chrome 版本相同的 Chrome 驅動程式。現在將該驅動程式儲存到 Python 檔案所在的同一資料夾中。
步驟 2 - 使用 START_URL= “https://www.indiatoday.in/science”。匯入 BeautifulSoup 用於解析。使用“class”作為“story__grid”來定位 div 元素。
步驟 3 - 指定網站 URL,並啟動驅動程式以獲取 URL。
步驟 4 - 使用 BeautifulSoup 解析獲取的頁面。
步驟 5 - 搜尋具有所需類名的 div 標籤。
步驟 6 - 提取內容。列印它並將其轉換為 html 格式,方法是在 HTML 標籤內包含提取的內容。
步驟 7 - 編寫輸出 HTML 檔案。執行程式。開啟輸出 HTML 檔案並檢查結果。
示例
from selenium import webdriver
from bs4 import BeautifulSoup
import time
START_URL= "https://www.indiatoday.in/science"
driver = webdriver.Chrome("./chromedriver")
driver.get(START_URL)
time.sleep(10)
def scrape():
temp_l=[]
soup = BeautifulSoup(driver.page_source, "html.parser")
for div_tag in soup.find_all("div", attrs={"class", "story__grid"}):
temp_l.append(str(div_tag))
print(temp_l)
enclosing_start= "<html><head><link rel='stylesheet' " + "href='styles.css'></head> <body>"
enclosing_end= "</body></html>"
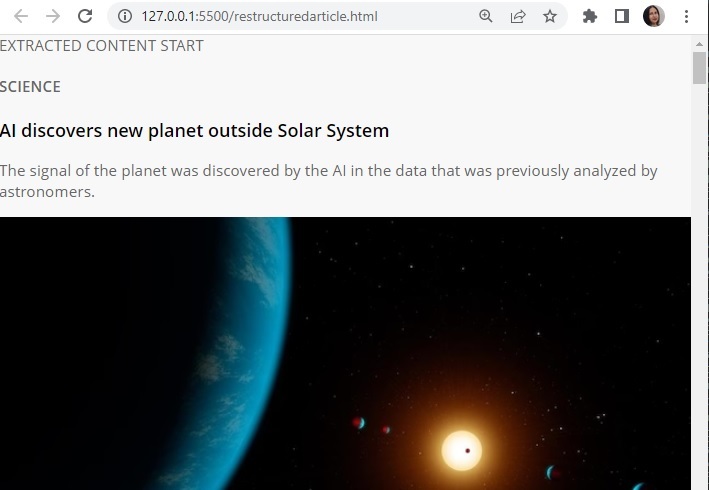
with open('restructuredarticle.html', 'w+', encoding='utf-16') as f:
f.write(enclosing_start)
f.write('\n' + '<p> EXTRACTED CONTENT START </p>'+'\n')
for items in temp_l:
f.write('%s' %items)
f.write('\n' + enclosing_end)
print("File written successfully")
f.close()
scrape()
輸出
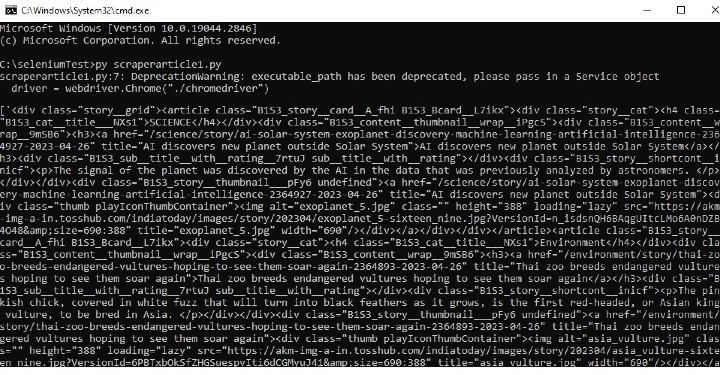
在命令視窗中執行 Python 檔案 -
開啟 cmd 視窗。首先,我們將在 cmd 視窗中檢查輸出。然後在瀏覽器中開啟儲存的 html 檔案以檢視提取的內容。
示例 2:使用 Selenium 和 Python 定位具有特定類名的 h4 元素
步驟 1 - 首先下載與 Chrome 版本相同的 chromedriver。現在將該驅動程式儲存到 Python 檔案所在的同一資料夾中。
步驟 2 - 使用 START_URL= “https://jamiatimes.in/”。匯入 BeautifulSoup 用於解析。使用“class”作為“entry-title title”來定位 h4 元素。
步驟 3 - 指定網站 URL,並啟動驅動程式以獲取 URL。
步驟 4 - 使用 BeautifulSoup 解析獲取的頁面。
步驟 5 - 搜尋具有所需類名的 h4 標籤。
步驟 6 - 提取內容。列印它並將其轉換為 html 格式,方法是在 HTML 標籤內包含提取的內容。
步驟 7 - 編寫輸出 HTML 檔案。執行程式。開啟輸出 HTML 檔案並檢查結果。
示例
from selenium import webdriver
from bs4 import BeautifulSoup
import time
START_URL= "https://jamiatimes.in/"
driver = webdriver.Chrome("./chromedriver")
driver.get(START_URL)
time.sleep(10)
def scrape():
temp_l=[]
soup = BeautifulSoup(driver.page_source, "html.parser")
for h4_tag in soup.find_all("h4", attrs={"class", "entry-title title"}):
temp_l.append(str(h4_tag))
enclosing_start= "<html><head><link rel='stylesheet' " + "href='styles.css'></head> <body>"
enclosing_end= "</body></html>"
with open('restructuredarticle2.html', 'w+', encoding='utf-16') as f:
f.write(enclosing_start)
f.write('\n' + '<p> EXTRACTED CONTENT START </p>'+'\n')
for items in temp_l:
f.write('%s' %items)
f.write('\n' + enclosing_end)
print("File written successfully")
f.close()
print(temp_l)
scrape()
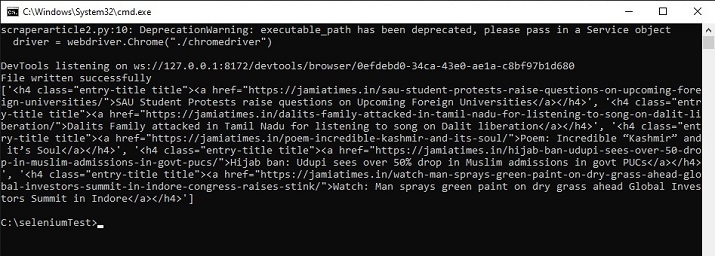
輸出
在命令視窗中執行 python 檔案 -
開啟 cmd 視窗。首先,我們將在 cmd 視窗中檢查輸出。然後在瀏覽器中開啟儲存的 html 檔案以檢視提取的內容。
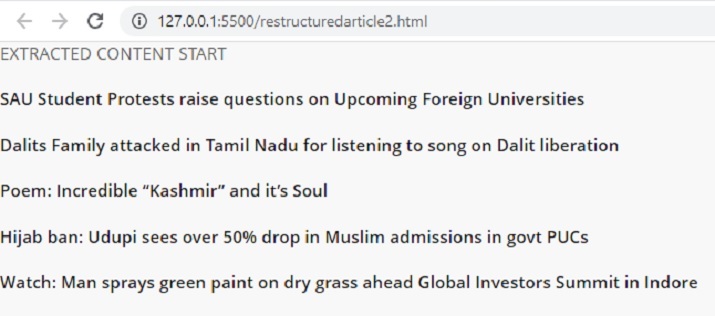
在這篇 Python Selenium 文章中,給出了兩個不同的示例,展示瞭如何定位元素進行抓取的方法。在第一個示例中,Selenium 用於定位 div 標籤,然後從新聞網站抓取指定的元素。在第二個示例中,定位了 h4 標籤,並從另一個新聞網站提取了所需的標題。

891 次瀏覽
