
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用SHAP值解釋機器學習模型
理解機器學習模型如何做出決策對於初學者來說可能感覺像魔法一樣。這篇博文中介紹了一種經常用來解釋這些決策的工具:SHAP值。在我們的學習結束後,您將更好地理解SHAP值如何幫助您解釋機器學習模型,因為我們將用簡單易懂的語言逐步講解其基本原理。
引言
在理解機器學習模型如何做出決策時,它們有時感覺像一個神秘的黑盒子。SHAP(SHapley Additive exPlanations)值允許我們檢視這個盒子內部,並觀察每個因素(例如年齡、身高或收入)如何影響模型的預測。本文將用簡單的解釋,引導您瞭解SHAP值的基礎知識。
模型解釋的重要性
一旦訓練好機器學習模型,它就可能變成一個黑盒子——這意味著它會給出預測結果,而不會解釋它是如何得出這些結果的。這可能是個問題,因為在醫療保健、金融和法律等敏感領域,理解模型如何做出決策至關重要。這就是模型解釋的用武之地。為了找出哪些特徵(輸入)對模型的決策影響最大,我們希望開啟這個“黑盒子”。例如,如果模型預測拒絕貸款,我們想知道為什麼。是年齡、信用評分還是收入決定的?這種透明度有助於公平、信任和問責制。
什麼是SHAP值?
SHAP值源於博弈論中的一個概念,稱為“Shapley值”。假設你和朋友們在玩遊戲,你想確定每個人對團隊獲勝的貢獻有多大。Shapley值透過根據每個參與者的貢獻公平地分配整體成功來實現這一點。SHAP值在機器學習中也採取類似的操作。SHAP(SHapley Additive exPlanations)方法使我們能夠理解某些特徵(例如年齡、財富或教育程度)如何影響模型的預測。SHAP值解釋了每個特徵對給定預測的正面或負面貢獻程度。
關鍵術語
在繼續之前,以下是一些您需要了解的關鍵術語:
| 術語 | 定義 |
| 特徵 | 資料中的特徵或變數(例如,收入、年齡或房屋大小)。 |
| 預測 | 機器學習模型的輸出,例如事件發生的可能性(例如,一個人是否會拖欠貸款?)。 |
| 模型 | 根據資料做出預測的系統或數學函式。 |
| 黑盒 | 一個做出預測但沒有提供其工作原理的模型。 |
| SHAP值 | 一種告訴我們每個特徵對模型預測貢獻多少的方法。 |
SHAP值的工作原理?
SHAP值的核心是為每個特徵分配一個數值,該數值表示它增加了或減少了模型預測的程度。讓我們用更簡單的術語來解釋:
- 基準值:如果我們事先對資料一無所知,這就是模型的平均預測。它類似於起點。
- 每個特徵的SHAP值:SHAP計算資料點中每個特徵的預測與其基準值之間的差異。
正SHAP值意味著該特徵提高了預測值。
負SHAP值意味著該特徵降低了預測值。
示例
假設一個模型根據三個特徵預測學生是否會透過考試:學習時間、睡眠質量和以往成績。
- 基準值(平均預測):50% 的通過幾率。
- 學習時間的SHAP值:+30%(學習時間越長,通過幾率越高)。
- 睡眠質量的SHAP值:-10%(睡眠質量差,通過幾率降低)。
- 以往成績的SHAP值:+20%(以往成績優秀,提高通過幾率)。
因此,這位學生的最終預測將是:
50% (base value) + 30% (studied) - 10% (sleep) + 20% (prior grades) = 90% chance of passing.
SHAP值的視覺化
SHAP的優點之一是它提供了模型工作原理的清晰視覺化解釋。一些常見的SHAP視覺化包括:
- SHAP摘要圖:顯示模型中所有預測中每個特徵的平均影響。它幫助我們瞭解哪些特徵總體上最重要。
- 依賴圖:顯示單個特徵如何影響預測。
- SHAP力圖:顯示每個特徵對單個預測的貢獻。它幫助我們解釋模型為什麼做出特定決策。
這些視覺化使SHAP對可能不是資料科學專家的使用者特別有用。
使用SHAP值解釋機器學習模型
在本節中,我們將透過一個例子來了解如何使用SHAP值解釋機器學習模型。為了更好地理解,我們將使用一個機器學習模型、顯示SHAP值並利用一個公開可用的資料集。我們將詳細講解每個步驟。我們將使用著名的波士頓房價資料集,該資料集提供了波士頓房屋的詳細資訊,經常用於迴歸分析(預測房價)。
步驟1:安裝所需的庫
首先,您需要安裝所需的Python庫。您可以使用pip來完成此操作。
pip install shap scikit-learn pandas matplotlib seaborn ipywidgets
步驟2:載入資料集
我們將直接從線上資源使用波士頓房價資料集。
import pandas as pd # Load the dataset url = "https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv" df = pd.read_csv(url) # Display the first few rows of the dataset df.head()
步驟3:資料預處理
在訓練模型之前,我們需要將資料分成特徵(輸入)和目標(輸出),並將其分成訓練集和測試集。
from sklearn.model_selection import train_test_split # Features (input) and target (output) X = df.drop(columns=['medv']) # Input features (everything except the target) y = df['medv'] # Target variable (house price) # Split the data into training and testing sets (80% train, 20% test) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) print(X_train.shape, X_test.shape)
步驟4:訓練模型
我們將使用隨機森林迴歸器根據特徵預測房價。這是一種常用的機器學習演算法,適用於迴歸任務。
from sklearn.ensemble import RandomForestRegressor
# Initialize the model
model = RandomForestRegressor(n_estimators=100, random_state=42)
# Train the model
model.fit(X_train, y_train)
# Test the model
predictions = model.predict(X_test)
# Check model performance
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
步驟5:使用SHAP解釋模型
現在我們已經訓練了一個模型,讓我們使用SHAP值來解釋它。
import shap # Initialize SHAP explainer explainer = shap.TreeExplainer(model) # Calculate SHAP values for the test set shap_values = explainer.shap_values(X_test) # Visualize the SHAP values for the first prediction shap.initjs() # Initialize JS visualization shap.force_plot(explainer.expected_value, shap_values[0], X_test.iloc[0])
輸出
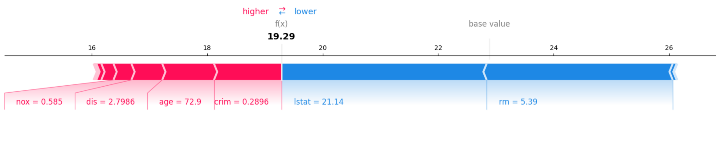
步驟6:視覺化SHAP摘要圖
摘要圖幫助我們瞭解所有預測中不同特徵的總體重要性。
# SHAP summary plotshap.summary_plot(shap_values, X_test)
輸出
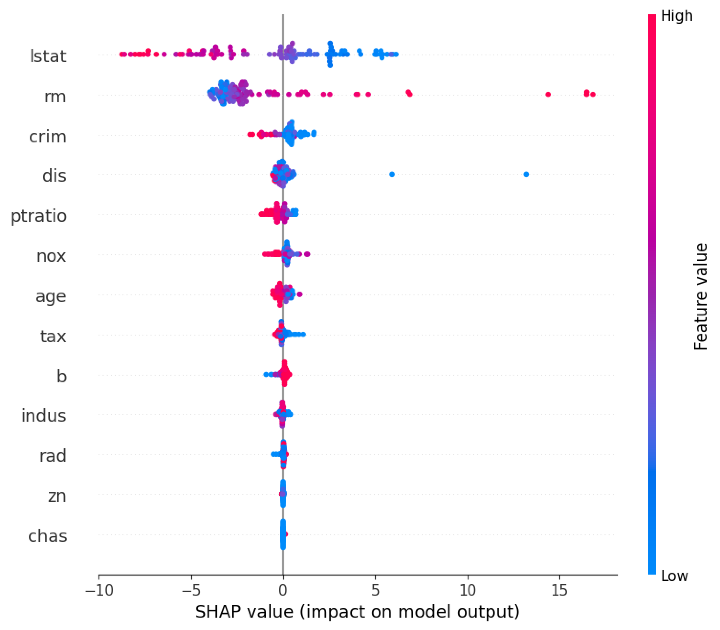
關於SHAP和模型解釋的常見問題
問:為什麼SHAP值比其他解釋模型的方法更好?
答:SHAP值基於可靠的數學理論(博弈論中的Shapley值)。它們在解釋特徵如何影響預測方面提供了前後一致性和公平性。問:SHAP可以與任何機器學習模型一起使用嗎?
答:SHAP可以與許多模型一起使用,包括決策樹、神經網路等等。問:SHAP值總是準確的嗎?
答:SHAP值提供了對模型預測的可靠解釋,但模型和資料質量都會影響值的準確性。結論
理解不同特徵如何影響模型的預測對於解釋機器學習模型越來越重要,而SHAP值為此提供了一個有用的工具。無論您是機器學習方面的專家,還是想更深入地瞭解模型解釋,SHAP都能透過提供透明度和洞察決策過程來幫助解開謎團。透過視覺化SHAP值,使用者可以輕鬆理解不同特徵的重要性,從而提高對AI系統的公平性和信任度。繼續學習,很快你就能自信地解釋你自己的模型!
75 次瀏覽
