
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP檢查資料集或特徵的正態性
介紹
從統計學角度來看,正態性是指屬於正態分佈或高斯分佈的現象。資料集的**正態性**是指檢驗資料集或變數是否遵循正態分佈。可以進行許多檢驗來檢查資料集的正態性,其中最流行的是直方圖法、QQ圖和KS檢驗。
正態性檢驗 – 檢查正態性
確定資料集或特徵的正態性既有統計方法,也有圖形方法。讓我們來看一下其中的一些方法。
圖形方法
直方圖
直方圖以條形圖的形式顯示特徵的分佈。每個條形代表特定值的出現頻率。它用於視覺化單個特徵。
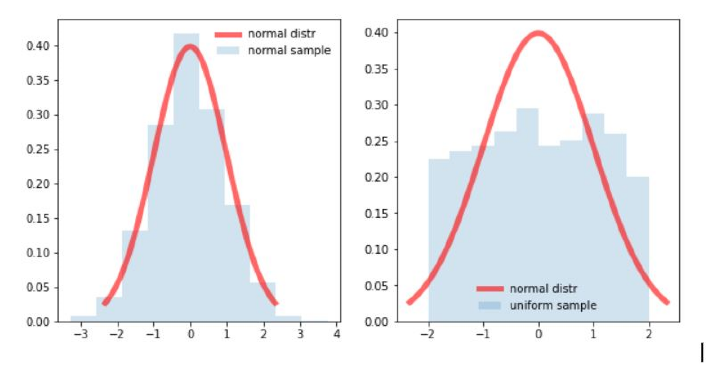
在上圖中,我們可以看到左圖比右圖更接近鐘形正態曲線。因此,我們可以推斷左圖是正態分佈。
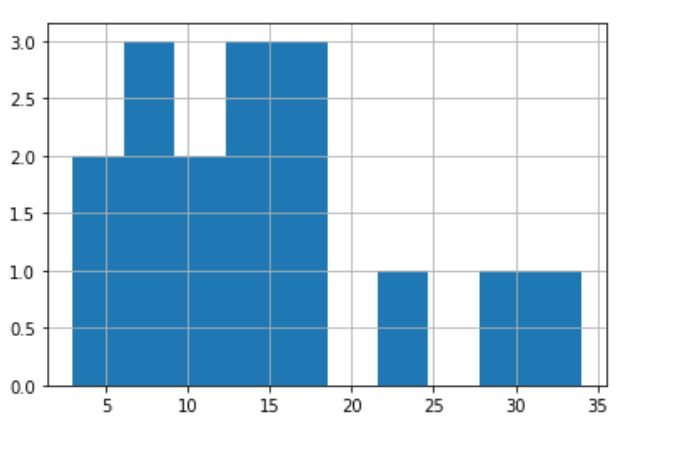
程式碼示例 [直方圖]
import pandas as pd df = pd.Series([11,12,13,14,15,16,17,18,8,3,5,7,9,23,30,34]) df.hist()
輸出
QQ圖
也稱為分位數-分位數圖,它更清晰地顯示了與正態分佈的偏差,因為它將實際分位數與理論分位數作圖。
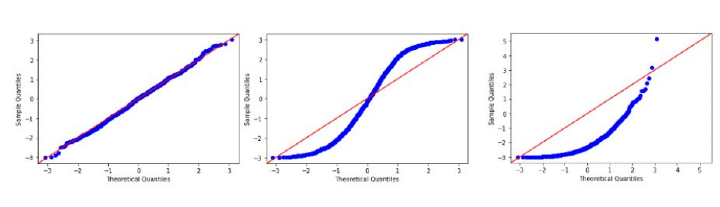
為了使資料或特徵遵循正態分佈,它應該更緊密地與上圖中的紅線對齊。在最左邊的影像中,我們可以說它遵循正態分佈,因為實際分位數與理論分位數一致。
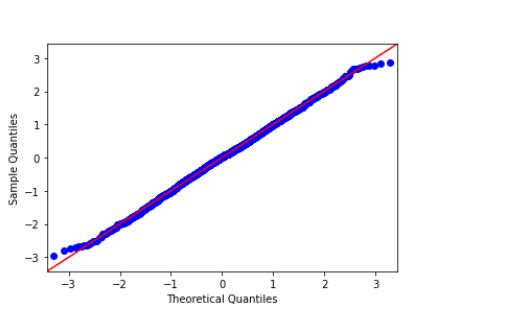
程式碼示例 [QQ圖]
import statsmodels.api as sapi from scipy.stats import norm as nm import matplotlib.pyplot as plt data = nm.rvs(size=2000) sapi.qqplot(data, line='45') plt.show()
輸出
統計方法
KS檢驗
KS檢驗代表 Kolmogorov-Smirnov 檢驗。它透過測量經驗分佈和理論分佈之間的距離來定義檢驗統計量。在KS檢驗中,Kolmogorov-Smirnov是檢驗統計量。我們尋找原假設為真,然後它遵循Kolmogorov分佈。P值可以決定是否接受或拒絕原假設。為了使資料遵循正態分佈,KS統計量的值應為0。
如果檢驗的P值大於0.05,我們得出結論:資料遵循正態分佈;如果P值小於0.05,我們認為是非正態分佈。
KS檢驗的缺點是它需要大量的數點才能拒絕原假設。異常值會影響KS檢驗。
程式碼示例 [KS檢驗]
from scipy.stats import norm,kstest
datapoints = norm.rvs(size=2000)
statks, pval = kstest(datapoints, 'norm')
print("statistics (KS) : ", statks,", pvalue : " ,pval)
輸出
statistics (KS) : 0.021882913017164163 , pvalue : 0.2894024815418249
Shapiro-Wilk檢驗
這是一個非常強大的正態性檢驗。它也用於其他分佈。
如果Wilk檢驗的P值大於0.05,我們得出結論:資料遵循正態分佈;如果P值小於0.05,我們認為是非正態分佈。
程式碼示例 [Wilk檢驗]
from scipy.stats import shapiro,norm
datapoints = norm.rvs(size=1000)
statistic_val,pval = shapiro(datapoints)
print("statistic : ", statistic_val,", pvalue : " ,pval)
輸出
statistic : 0.9993162155151367 , pvalue : 0.9813627600669861
結論
資料集或特徵的正態性是資料分析中一個非常理想的特性。有很多很好的正態性檢驗,包括圖形方法和統計方法。正態資料集在機器學習和資料科學中被認為是標準的,因為它包含有用的資訊,並且大多數自然現象的資料都表現出正態性。

307 次瀏覽
