
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP什麼是深度學習中的PointNet?
PointNet 透過直接使用原始資料進行分析點雲,無需進行體素化或其他預處理步驟。斯坦福大學的一位研究人員於 2016 年提出了這種新穎的架構,用於對影像的 3D 表示進行分類和分割。
關鍵屬性
在點雲中,PointNet 考慮了點集的幾個關鍵屬性。
點雲由非結構化的點集組成,並且在一個點雲中可能存在多個排列。如果我們有 N 個點,則有 N!有幾種方法可以對它們進行排序。使用排列不變性,PointNet 確保分析獨立於不同的排列。因此,無論點的順序如何,網路都應產生一致的結果。PointNet 旨在尊重此屬性,能夠應對點雲中的不規則性並捕獲基本特徵,而不會受到點順序的影響。
在不同的變換(如旋轉和平移)下,PointNet 的分類和分割結果應保持一致。無論物件或點雲中片段的位置、方向或位置如何,網路都應能夠識別和分類它們。PointNet 透過整合變換不變性來確保學習到的特徵和表示的魯棒性。即使存在幾何變換,網路也能很好地泛化並做出準確的預測。
點之間的互動
雖然點雲中的每個點都包含有價值的資訊,但相鄰點之間的關係和連線在理解底層結構方面也起著關鍵作用。特別是,PointNet 認識到這些互動的重要性。透過考慮區域性上下文和相鄰點之間的關係,網路能夠透過考慮區域性上下文來準確地分割點雲的不同部分。透過利用點區域性鄰域中存在的大量資訊,PointNet 可以獲得卓越的分割結果。
PointNet 架構
透過整合這些屬性,PointNet 提供了一個強大的架構來分析點雲。透過這樣做,它克服了傳統方法的侷限性,這些方法需要體素化或其他中間表示。PointNet 能夠處理無序集、其變換不變性和其對點互動的依賴性,實現了對 3D 表示進行分類和分割的統一且有效的方法。
PointNet 使研究人員和從業人員能夠直接處理原始點雲資料,並在各種 3D 識別任務中實現最先進的效能。除了增強我們對 3D 形狀和物件的理解之外,這一突破還為機器人技術、計算機輔助設計和增強現實等領域開闢了新的可能性。未來,PointNet 將推動點雲分析的令人興奮的進步。PointNet 的一個基本方面是它使用稱為最大池化的對稱函式來處理無序輸入集。為了使網路能夠從點雲中學習並從中提取有價值的資訊,此功能至關重要。
最大池化允許 PointNet 透過學習一組最佳化函式來識別點雲中有趣且資訊豐富的點。正是這些選定的點使網路能夠透過編碼其重要性的原因來捕獲 3D 形狀或物件的本質特徵。PointNet 架構的最終全連線層將這些學習到的最優值聚合到全域性描述符中。可以從該全域性描述符中獲得對形狀的整體理解,該描述符可用於形狀分類。此外,相同的聚合特徵也可用於預測各個點的標籤,從而促進形狀分割。
PointNet 的輸入格式可以對資料進行剛性或仿射變換。可以獨立地變換每個點,從而易於操作和預處理。可以透過利用此特性引入資料相關的空間變換網路。在 PointNet 處理資料之前,此空間變換網路一致地對齊資料以使其規範化。新增此步驟進一步提高了網路結果的準確性和魯棒性。
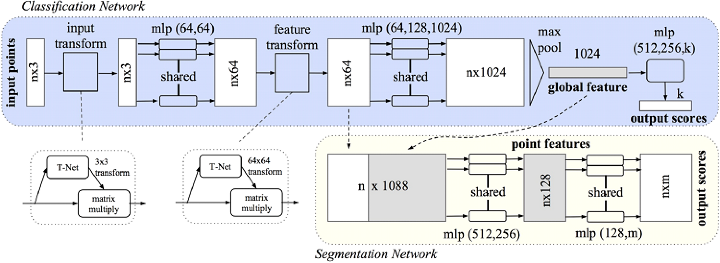
下圖顯示了 PointNet 架構的視覺化表示。分類網路的輸入中有 n 個點。在應用輸入和特徵變換後,它使用最大池化聚合點特徵。此過程的結果是,m 個預定義類別將接收分類分數。該架構透過連線全域性和區域性特徵來擴充套件分割任務。多層感知器由表示法“mlp”表示,其中層大小由括號指示。對於最終的多層感知器,使用整流線性單元 (ReLU) 對所有層應用批次歸一化。
Python 示例
以下是一個在自定義資料集上訓練 PointNet 模型的程式碼片段示例:
import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers # Define the number of points and classes NUM_POINTS = 2048 NUM_CLASSES = 10 # Define your dataset and labels train_points = np.random.randn(NUM_POINTS, 3) train_labels = np.random.randint(NUM_CLASSES, size=NUM_POINTS) test_points = np.random.randn(NUM_POINTS, 3) test_labels = np.random.randint(NUM_CLASSES, size=NUM_POINTS) # Define the PointNet model architecture inputs = keras.Input(shape=(NUM_POINTS, 3)) x = layers.Conv1D(64, kernel_size=1, activation="relu")(inputs) x = layers.BatchNormalization()(x) x = layers.Conv1D(64, kernel_size=1, activation="relu")(x) x = layers.BatchNormalization()(x) # Apply max pooling to aggregate point features x = layers.GlobalMaxPooling1D()(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dropout(0.4)(x) x = layers.Dense(128, activation="relu")(x) x = layers.Dropout(0.4)(x) outputs = layers.Dense(NUM_CLASSES, activation="softmax")(x) model = keras.Model(inputs=inputs, outputs=outputs, name="pointnet") model.summary() # Compile and train the model model.compile( loss="sparse_categorical_crossentropy", optimizer=keras.optimizers.Adam(learning_rate=0.001), metrics=["accuracy"], ) model.fit( train_points, train_labels, batch_size=32, epochs=10, validation_data=(test_points, test_labels) )
實際場景需要預處理您的資料集並將其載入到 train_points、train_labels、test_points 和 test_labels 變數中。根據您的具體問題和資料特徵,您可能需要調整模型架構和超引數。

148 次瀏覽
