
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL JavaScript
JavaScript PHP
PHP訓練集、測試集和驗證集
在本文中,我們將學習訓練集、測試集和驗證集之間的區別。
引言
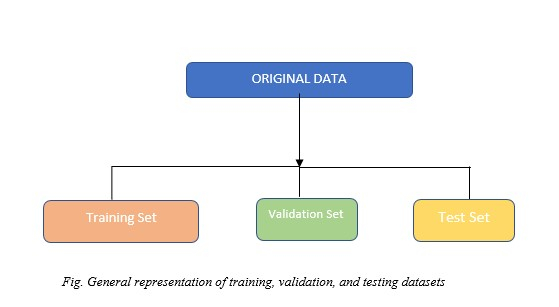
資料分割是我們可以在機器學習/深度學習任務中使用的最簡單的預處理技術之一。原始資料集被分割成子集,例如訓練集、測試集和驗證集。這樣做的主要原因之一是解決過擬合問題。但是,它還有其他好處。讓我們簡要了解一下這些術語,並看看它們如何發揮作用。
訓練集
訓練集用於擬合或訓練模型。這些資料點用於學習模型的引數。就大小而言,它是所有集合中最大的一組。在監督學習的情況下,訓練集包括特徵和標籤。在無監督學習的情況下,它可以僅僅是特徵集。這些標籤用於訓練階段以獲得訓練精度分數。訓練集通常佔原始資料集的 70%,但可以根據用例或可用資料進行更改。
例如
在使用線性迴歸時,訓練集中的點用於繪製最佳擬合線。
在 K 近鄰演算法中,訓練集中的點是可以作為鄰居的點。
訓練集的應用
訓練集用於資料探勘中的監督學習程式(即記錄分類或連續目標值的預測)。
示例
Let’s consider a dataset containing 20 points Dataset1 = [1,5,6,7,8,6,4,5,6,7,23,45,12,34,45,1,7,7,8,0] Train set can be taken as 60 % of the original Dataset1 The train set will contain 12 data points [8,6,4,5,6,7,23,45,12,34,1,5]
驗證集
驗證集用於在模型的超引數調整過程中提供對模型擬合的無偏評估。它是用於更改學習過程引數的示例集。針對使用訓練集訓練的模型測試超引數的最佳值。在機器學習或深度學習中,我們通常需要測試具有不同超引數的多個模型,並檢查哪個模型產生最佳結果。此過程藉助驗證集來執行。
例如,在深度 LSTM 網路中,驗證集用於查詢隱藏層的數量、節點的數量、密集單元的數量等。
驗證集的應用
驗證集用於人工智慧模型的超引數調整。領域包括醫療保健、分析、網路安全等。
示例
Let’s consider a dataset containing 20 points Dataset2 = [1,5,6,7,8,6,4,5,6,7,23,45,12,34,45,1,7,7,8,0] The validation set can be taken as 20 % of the original Dataset2. The validation set will contain 4 data points [45,1,7,7]
測試集
一旦我們使用訓練集訓練了模型,並使用驗證集調整了超引數,我們就需要測試該模型是否可以很好地泛化到未見資料。為此,使用測試集。在這裡,我們可以檢查和比較訓練精度和測試精度。為了確保模型沒有過擬合或欠擬合,測試精度非常有用。如果訓練精度和測試精度之間存在很大差異,則可能發生了過擬合。
選擇測試集時,應牢記以下幾點:
測試應包含與訓練集相同的特徵。
它應該足夠大以產生具有統計意義的結果。
測試集的應用
Test sets are used for evaluating metrics like: Precision, Recall, AUC - ROC Curve, F1-Score
示例
Let's consider a data set containing 20 points Dataset3 = [1,5,6,7,8,6,4,5,6,7,23,45,12,34,45,1,7,7,8,0] The test set can be taken as 20 % of the original Dataset2 The test set will contain 4 data points [6,7,8,0]
為什麼我們需要訓練集、驗證集和測試集?
訓練集是訓練模型並學習引數所必需的。幾乎所有機器學習/深度學習任務都應該至少包含一個訓練集。
驗證集和測試集是可選的,但強烈建議使用,因為只有這樣才能驗證訓練模型的可讀性和準確性。如果我們不選擇執行超引數調整或模型選擇,則可以省略驗證集。在這種情況下,訓練集和測試集就可以完成這項工作。
評估模型的一種巧妙方法是使用 K 折交叉驗證。
下表總結了訓練集、驗證集和測試集。
| 訓練集 | 驗證集 | 測試集 |
|---|---|---|
| 用於擬合模型以學習模型的引數。 | 用於在模型的超引數調整過程中提供對模型擬合的無偏評估。 | 用於測試模型是否可以很好地泛化到未見資料。 |
| 大小比驗證集和測試集大。 | 較小。 | 大小比訓練集小。 |
| 在監督學習中,它包含特徵和標籤。在無監督學習中,它只包含特徵。 | 在監督學習中包含特徵和標籤,在無監督學習中只包含特徵。 | 在監督學習中包含特徵和標籤,在無監督學習中只包含特徵。 |
| 在較大的資料集上速度較慢,但可以使用多處理並行執行該作業。 | 如果觀察到的超引數很大,則通常在單核上速度較慢。可以並行執行。 | 比訓練集和驗證集都快。用於根據訓練的模型獲取測試資料的指標。 |
結論
分割用於訓練、驗證和測試的資料集是任何機器學習或深度學習用例中的一個核心任務。它非常簡單,易於實現,並且可以解決一些非常常見的問題,例如過擬合和欠擬合。

6000+ 次瀏覽
