
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPTensorFlow 中的 TfLearn 及其安裝
TFlearn 是一個基於 TensorFlow 框架構建的開源深度學習庫。它提供了一個高階 API,可以輕鬆建立和訓練不同的神經網路模型。
它提供了一系列預先存在的模型,例如卷積神經網路 (CNN)、深度神經網路 (DNN) 和許多其他模型。它還包括各種啟用函式,例如 ReLU(修正線性單元)、softmax,以及諸如分類交叉熵之類的損失函式。
由於不需要廣泛瞭解 TensorFlow 中的神經網路 API,TfLearn 是初學者的理想庫。它是一個簡單易用的庫,我們可以定義輸入、隱藏和輸出層,而不是構建計算密集型網路架構,例如 AlexNet 或 LeNet 架構。
如何使用 TfLearn?
首先,檢查系統中是否存在 Python。可以透過列印系統中存在的 Python 版本來檢查。
python ---version
如果你的系統中未安裝 Python,可以訪問“python.org”網站安裝 Python 3.8 或更高版本。
之後,檢查你的系統中是否安裝了 TensorFlow 模組。可以透過執行以下命令來完成:
pip install tensorflow
在這種情況下,TensorFlow 已安裝。如果它不存在,它將安裝該模組到你的系統中。
之後,使用以下命令將 TfLearn 模組安裝到你的系統中:
pip install tflearn

現在我們已經下載了所有先決條件,讓我們來看一個使用 TfLearn 的示例。
示例 1
在下面的程式中,使用 MNIST 資料集來訓練和測試我們的模型。TfLearn 預設在其軟體包中提供 MNIST 資料集。因此,我們可以使用它。
為了提高預測精度,並使計算機能夠理解影像,我們使用獨熱編碼的概念來定義 [0,...,9] 中的類別。資料集實際上是以手寫數字的形式存在的。
演算法
匯入所有庫。
載入 MNIST 資料集並將值賦給 x_train、y_train、x_test 和 y_test,其中 x 表示資料集中的值,y 表示標籤。
將 x_train 和 x_test 轉換為浮點值,並透過除以 255 將其畫素值轉換為 0 或 1。
定義 10 個子圖,並透過初始化 for 迴圈來自動縮放其影像比例,將影像列印到子圖上。
列印影像。
import tflearn
from tflearn.datasets import mnist
import matplotlib.pyplot as plt
(x_train, y_train),(x_test,y_test)=mnist.load_data()
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
x_train, x_test=x_train/255.0, x_test/255.0
#To show the dataset
fi,ax=plt.subplots(10,10)
k=0
for i in range(10):
for j in range(10):
ax[i][j].imshow(x_train[k].reshape(28,28), aspect='auto')
k+=1
plt.show()
我們載入資料集並將其分成訓練資料和測試資料。然後,我們將訓練和測試資料的型別轉換為 float32,並透過將影像的畫素值除以 255.0 來對其進行歸一化,以便它們在 0 和 1 的範圍內。
我們建立一個 10x10 的網格,並初始化一個指標來跟蹤影像索引。我們使用迴圈遍歷網格。對於每個網格框,我們顯示來自訓練集的影像,該影像將影像從一維陣列重新整形為具有 28x28 維度的二維陣列。
輸出

示例 2
在前面的示例中,我們載入了未進行獨熱編碼的 MNIST 資料。在下面的示例中,我們將列印應用獨熱編碼後訓練和測試標籤的形狀,並列印訓練標籤的前五行。
演算法
使用 tflearn 匯入 MNIST 資料集。
載入具有獨熱編碼值的 MNIST 資料集。
列印資料集的形狀和維度。
列印訓練標籤的前五行。
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
print("Training Data shape: ", x_train.shape)
print("Training Labels shape: ", y_train.shape)
print("Testing Data shape: ", x_train.shape)
print("Testing Labels shape: ", y_train.shape)
print("First 5 training labels: ")
print(y_train[:5])
在這裡,我們載入包含數字手寫影像的 MNIST 資料集。然後,我們將訓練影像和標籤分配給單獨的變數,同樣地,將測試影像和標籤分配給單獨的變數。
one_hot = true 引數確保標籤以獨熱編碼格式表示,這是一種以二進位制向量格式表示所需資料的表示方法,其中一個元素固定為熱 (1),其餘元素表示為冷 (0)。這裡熱元素是所需的靶元素。
然後,我們列印測試和訓練資料(影像和標籤)。
輸出

構建神經網路模型
現在我們已經瞭解了我們正在處理的內容,讓我們構建我們的神經網路模型。神經網路包含三個層,即:
輸入層
隱藏層
輸出層
示例 3
為了在我們的神經網路中構建這些層,我們使用 TfLearn 模組。
我們在隱藏層中定義具有 256 個層的神經網路,並使用 ReLU 啟用函式,以及包含 10 個層和 softmax 啟用函式的輸出層。在大多數神經網路架構中,輸出層總是具有 softmax 啟用函式。
然後,我們使用 SGD(隨機梯度下降)最佳化器和分類交叉熵損失函式以及 0.1 的學習率來定義模型。有了這些,我們構建我們的模型並將其擬合到我們的訓練資料和測試資料,然後我們列印模型的精度。
演算法
匯入所有庫。
載入 MNIST 資料集並將值賦給 x_train、y_train、x_test 和 y_test,其中 x 表示資料集中的值,y 表示標籤。
匯入資料集時設定 one_hot=True。
列印所有變數的形狀。
將輸入層定義為 [None,784]。
對於隱藏層,將輸入層與 256 層以及 ReLU 啟用函式等同起來。
對於輸出層,新增 10 層以及 softmax 啟用函式。
使用必要的最佳化器和損失函式編譯模型並列印精度。
import tflearn
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
print("Training Data shape: ", x_train.shape)
print("Training Labels shape: ", y_train.shape)
print("Testing Data shape: ", x_train.shape)
print("Testing Labels shape: ", y_train.shape)
print("First 5 training labels: ")
print(y_train[:5])
i_layer=tflearn.input_data(shape=[None,784])
h_layer=tflearn.fully_connected(i_layer, 256, activation='relu')
o_layer=tflearn.fully_connected(h_layer, 10, activation='softmax')
net=tflearn.regression(o_layer, optimizer='sgd', learning_rate=0.1,
loss='categorical_crossentropy')
model=tflearn.DNN(net)
model.fit(x_train, y_train, validation_set=(x_test,y_test),
n_epoch=20, batch_size=128)
acc=model.evaluate(x_test,y_test)
print("Accuracy: ", acc)
我們透過從 MNIST 載入資料集將資料分成訓練資料和測試資料。然後,我們將獨熱編碼格式應用於標籤。然後,我們定義神經網路的架構並設定網路的訓練引數,例如學習率、損失函式等。
然後,我們對訓練資料進行 20 個 epoch 的訓練,並在訓練過程中驗證模型在測試資料上的效能。然後,我們對測試資料評估訓練好的模型並計算精度。
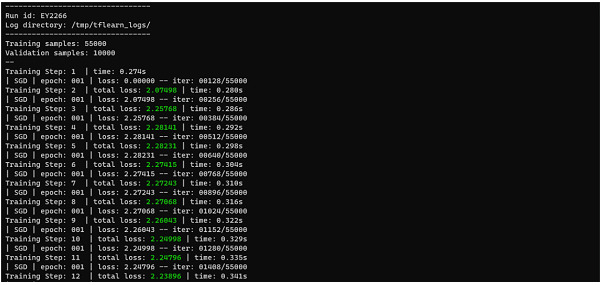
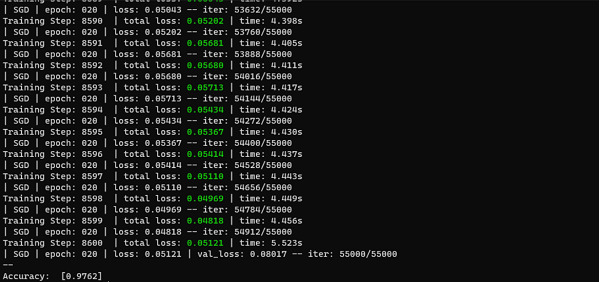
輸出
示例 4
在上面的示例中,我們可以看到我們的精度率為 97.5%,這非常好。透過這種方式,我們可以透過更改最佳化器和損失函式來微調模型的精度。在這個示例中,我們看到了使用 Adam 最佳化器。
演算法
匯入所有庫。
載入 MNIST 資料集並將值賦給 x_train、y_train、x_test 和 y_test,其中 x 表示資料集中的值,y 表示標籤。
匯入資料集時設定 one_hot=True。
列印所有變數的形狀。
將輸入層定義為 [None,784]。
對於隱藏層,將輸入層與 256 層以及 ReLU 啟用函式等同起來。
對於輸出層,新增 10 層以及 softmax 啟用函式。
使用必要的最佳化器和損失函式編譯模型並列印精度。
import tflearn
from tflearn.datasets import mnist
x_train, y_train, x_test, y_test=mnist.load_data(one_hot=True)
i_layer=tflearn.input_data(shape=[None,784])
h_layer=tflearn.fully_connected(i_layer, 256, activation='relu')
o_layer=tflearn.fully_connected(h_layer, 10, activation='softmax')
net=tflearn.regression(o_layer, optimizer='adam', learning_rate=0.1,
loss='categorical_crossentropy')
model=tflearn.DNN(net)
model.fit(x_train, y_train, validation_set=(x_test,y_test),
n_epoch=20, batch_size=128)
acc=model.evaluate(x_test,y_test)
輸出
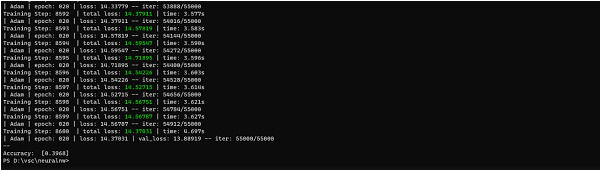
對於所示模型來說,這非常低,因此我們將 SGD 最佳化器用於我們的目的。
結論
如上所示,TfLearn 是一個非常簡單易懂的庫,用於構建深度學習模型。但是,由於它是一個非常簡單的庫,因此它不像 TensorFlow 或 PyTorch 這些庫那樣支援許多啟用函式或損失函式。與上述庫相比,它在模型定製方面也存在顯著不足。
該庫在計算機視覺中用於影像分割、目標檢測等任務,藉助卷積神經網路,以及在演算法可以構建並在教育環境中教授的教育和研究領域。

瀏覽量 108 次
