
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP多級佇列 (MLQ) CPU排程
介紹
使用多級佇列 (MLQ) 進行 CPU 排程是一種在 Linux 和 Windows 中實現的排程技術,用於安排系統 CPU 上的程序執行。MLQ 將程序劃分為多個等待佇列,每個佇列具有不同的優先順序。每個佇列可以使用其自己的排程演算法,允許作業系統以不同的方式優先處理不同型別的程序。
執行 MLQ 排程演算法有幾種方法。一種常用方法是將程序分成兩個單獨的等待佇列,前臺佇列比後臺程序佇列具有更高的優先順序。使用先到先服務 (FCFS) 排程演算法在每個佇列中分配時間片。
在本文中,我們將討論多級佇列 (MLQ) CPU 排程、其各種方法、元件、用例和示例。
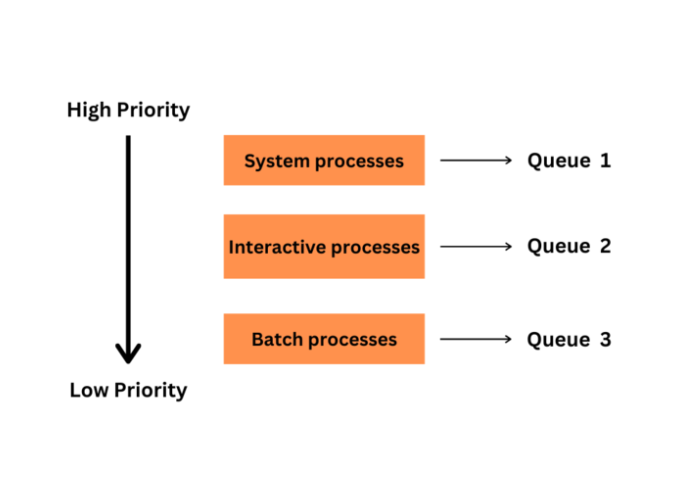
多級佇列 (MLQ) CPU 排程方法
以下是 MLQ CPU 排程的一些方法:
多級反饋佇列 (MLFQ) − MLFQ 方法是多級佇列排程演算法的一種變體。它使用多個具有不同優先順序的佇列,併為每個佇列中的程序分配時間片。但是,MLFQ 演算法允許程序根據其行為在佇列之間移動。
使用過多 CPU 時間或具有更高優先順序的程序可能會被移動到更高優先順序的佇列,而等待 I/O 或 CPU 使用率低的程序可能會被降級到較低優先順序的佇列。這種動態行為允許系統適應不斷變化的程序需求。
多級優先順序佇列 − 在多級優先順序佇列方法中,每個佇列都分配不同的優先順序級別,並且根據其優先順序排程程序。具有更高優先順序的程序優先執行,在低優先順序程序之前執行。這種方法適用於優先順序排程至關重要的系統,例如即時系統。
多級佇列 (MLQ) CPU 排程的元件
現在讓我們討論多級佇列 (MLQ) CPU 排程的元件。
佇列 − 多級佇列排程演算法由多個佇列組成,每個佇列具有不同的優先順序級別。根據其優先順序或其他標準將程序分配給這些佇列。每個佇列可以有其自己的排程演算法或策略。
排程策略 − 多級佇列排程演算法中的每個佇列都可以有其自己的排程策略或演算法。常見的排程策略包括先到先服務 (FCFS)、輪詢 (RR)、最短作業優先 (SJN) 或優先順序排程。這些策略確定從佇列中選擇程序執行的順序。
排程程式 − 排程程式負責從最高優先順序的非空佇列中選擇一個程序,並將 CPU 分配給該程序。它處理上下文切換、從 CPU 載入和解除安裝程序以及執行選定的程序。
多級佇列 (MLQ) CPU 排程的用例
分時系統 − 多級佇列排程通常用於分時系統,在分時系統中,多個使用者共享系統資源。佇列可用於優先處理互動式使用者程序、後臺任務和系統守護程序,確保資源的公平分配和響應迅速的使用者體驗。
伺服器環境 − 在伺服器環境中,不同型別的任務或服務可能具有不同的重要性級別或響應時間要求。多級佇列排程允許將關鍵服務或高優先順序任務優先於低優先順序後臺任務,確保及時完成重要任務。
示例
在這個例子中,python 程式碼演示了一個基於優先順序佇列的簡單程序排程演算法。它為不同的優先順序級別建立三個佇列:高、中和低。程序被入隊到各自的佇列中。然後,程式碼按優先順序順序檢查佇列並執行第一個可用程序。在這個例子中,高優先順序程序“程序 A”從高優先順序佇列中被選中並執行,因為它是在高優先順序佇列中存在的第一個程序。
from queue import Queue
# Create multiple queues for different priority levels
high_priority_queue = Queue()
medium_priority_queue = Queue()
low_priority_queue = Queue()
# Enqueue processes into their respective queues
high_priority_queue.put("Process A")
medium_priority_queue.put("Process B")
low_priority_queue.put("Process C")
# Process scheduling
if not high_priority_queue.empty():
process = high_priority_queue.get()
print("Executing high-priority process:", process)
elif not medium_priority_queue.empty():
process = medium_priority_queue.get()
print("Executing medium-priority process:", process)
elif not low_priority_queue.empty():
process = low_priority_queue.get()
print("Executing low-priority process:", process)
else:
print("No processes in the queues.")
輸出
Executing high-priority process: Process A
優點
應用多級佇列 (MLQ) 排程 CPU 方法具有多個優點,例如:
提高系統響應能力 − MLQ 方法透過為不同型別的程序設定優先順序,確保更高優先順序的程序更快地執行,從而使系統更具響應能力。
更好的資源利用率 − MLQ 技術允許不同的佇列使用不同的排程演算法,從而幫助確保更有效地利用資源。
支援不同型別的程序 − MLQ 演算法可以適應各種具有不同調度需求的程序。
靈活性 − 透過調整佇列的數量、每個佇列使用的排程演算法以及確定應分配哪個程序的引數,可以根據不同系統的需求定製 MLQ 演算法。
缺點
應用多級佇列 (MLQ) 排程 CPU 方法也有一些缺點,例如:
複雜性 − 與先到先服務或輪詢等更簡單的排程演算法相比,MLQ 演算法可能更復雜。
開銷 − 維持多個佇列可能會導致系統開銷。佇列越多,處理它們所需的 CPU 時間就越多,這可能會降低系統的整體效率。
低效 − 在某些情況下,MLQ 演算法可能不如其他排程演算法(例如最短作業優先 (SJF) 或優先順序排程)有效。
實現複雜 − 在實現 MLQ 演算法時,必須仔細考慮佇列總數、每個佇列使用的排程演算法以及確定應將程序分配給哪個佇列的引數。
結論
多級佇列 (MLQ) CPU 排程演算法是一種可以提高系統效率並確保更有效利用資源的排程演算法。透過將程序分成多個具有不同優先順序和排程演算法的佇列,MLQ 演算法可以提高系統靈活性、防止低優先順序程序餓死以及支援具有不同調度需求的不同型別的程序。
MLQ 演算法可能會增加系統開銷,在某些情況下效率較低,並且由於比更簡單的排程演算法更復雜,因此存在實現問題。因此,在決定是否使用 MLQ 演算法或其他排程演算法時,必須仔細考慮系統的特定需求以及相關的權衡。

759 次瀏覽
