
 資料結構
資料結構 網路
網路 RDBMS
RDBMS 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJava程式:移除給定棧中的重複元素
在本文中,我們將探討兩種在Java中從棧中移除重複元素的方法。我們將比較使用**巢狀迴圈**的直接方法和使用HashSet的更高效的方法。目標是演示如何最佳化重複元素移除並評估每種方法的效能。
問題陳述
編寫一個Java程式,從棧中移除重複元素。
輸入
Stack<Integer> data = initData(10L);
輸出
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
要從給定棧中移除重複元素,我們有兩種方法:
生成和克隆隨機棧
下面的Java程式首先構建一個隨機棧,然後建立它的副本以供進一步使用:
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData 用於建立一個指定大小的棧,其中包含1到100之間的隨機元素。
manualCloneStack 透過複製另一個棧中的資料來生成資料,用於比較兩種方法的效能。
使用樸素方法從給定棧中移除重複元素
以下是使用樸素方法從給定棧中移除重複元素的步驟:
- 啟動計時器。
- 建立一個空棧來儲存唯一元素。
- 使用while迴圈迭代,直到原始棧為空,彈出頂部元素。
- 使用resultStack.contains(element)檢查重複項,檢視元素是否已在結果棧中。
- 如果元素不在結果棧中,則將其新增到resultStack。
- 記錄結束時間並計算總花費時間。
- 返回結果
示例
以下是使用樸素方法從給定棧中移除重複元素的Java程式:
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack < > ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
對於樸素方法,我們使用
while (!stack.isEmpty()) resultStack.contains(element)
用於檢查元素是否已存在。使用最佳化方法(HashSet)從給定棧中移除重複元素
以下是使用最佳化方法從給定棧中移除重複元素的步驟:
- 啟動計時器
- 建立一個Set來跟蹤已檢視的元素(用於O(1)複雜度檢查)。
- 建立一個臨時棧來儲存唯一元素。
- 使用while迴圈迭代,直到棧為空。
- 從棧中移除頂部元素。
- 為了檢查重複項,我們將使用seen.contains(element)來檢查元素是否已在集合中。
- 如果元素不在集合中,則將其新增到seen和臨時棧中。
- 記錄結束時間並計算總花費時間。
- 返回結果
示例
以下是使用HashSet從給定棧中移除重複元素的Java程式:
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start));
return tempStack;
}
對於最佳化方法,我們使用
Set<Integer> seen結合使用兩種方法
以下是使用上述兩種方法從給定棧中移除重複元素的步驟:
- 初始化資料,我們使用initData(Long size)方法建立一個填充有隨機整數的棧。
- 克隆棧,我們使用cloneStack(Stack stack)方法建立原始棧的精確副本。
- 使用initData生成初始棧。
- 使用cloneStack克隆此棧。
- 對原始棧應用樸素方法以移除重複元素。
- 對克隆棧應用最佳化方法以移除重複元素。
- 顯示每種方法花費的時間以及兩種方法產生的唯一元素。
示例
以下是使用上述兩種方法從棧中移除重複元素的Java程式:
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack<Integer> initData(Long size) {
Stack<Integer> stack = new Stack<>();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack<Integer> cloneStack(Stack<Integer> stack) {
Stack<Integer> newStack = new Stack<>();
newStack.addAll(stack);
return newStack;
}
public static Stack<Integer> idea1(Stack<Integer> stack) {
long start = System.nanoTime();
Stack<Integer> resultStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack<Integer> data1 = initData(10L);
Stack<Integer> data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " + idea1(data1));
System.out.println("Unique elements using idea2: " + idea2(data2));
}
}
輸出
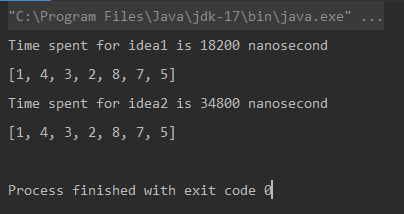
比較
* 測量單位為納秒。
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| 方法 | 100個元素 | 1000個元素 | 10000個元素 |
100000個元素 |
1000000個元素 |
| 方法1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| 方法2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
如觀察到的,方法2的執行時間短於方法1,因為方法1的複雜度為O(n²) ,而方法2的複雜度為O(n)。因此,當棧的數量增加時,計算所花費的時間也會相應增加。

更新於:2024年8月14日
208 次瀏覽

廣告