
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython 中的 Vaex 簡介
在資料科學領域,我們需要考慮的一個重要方面是處理大型資料集。當涉及到記憶體管理和執行速度時,處理如此大量的資料確實是一個挑戰。
Vaex 是一個專門為解決此類問題而設計的 Python 庫。它對於核心外資料幀(類似於 Pandas)特別有用,因為計算僅在必要時才執行。它在大型資料分析、操作和視覺化方面提供了良好的解決方案。在這篇文章中,我們將探討 Vaex 的概念、其功能以及如何在 Python 中使用它。
它利用現代技術的優勢,例如多核 CPU 和 SSD,來實現快速有效的計算。
為什麼我們需要 Vaex?
Vaex 的延遲評估、虛擬列、記憶體對映、視覺化以及利用表示式系統來實現高效計算和減少記憶體使用等功能,使我們能夠高效快速地處理海量資料集。Vaex 有可能克服其他庫(包括 pandas)中發現的各種限制。
Vaex 入門
我們可以透過兩種方式安裝 vaex:
使用 Pip:pip install --upgrade vaex
使用 Conda:conda install -c conda-forge vaex
安裝完成後,您可以按如下方式匯入和使用它:
import vaex
讀取資料效能
Vaex 讀取大型表格資料的速度比 pandas 快得多。讓我們透過將大小相同的資料集載入到這兩個庫中來進行分析。在這裡,我將使用 vaex 提供的資料集。如果您想獲得良好的結果並觀察 Vaex 和 Pandas 的效能差異,請嘗試使用大型資料集。從本質上講,如果您在 Python 中處理大量資料集,那麼 Vaex 可能是您的理想庫。
Vaex 的效能
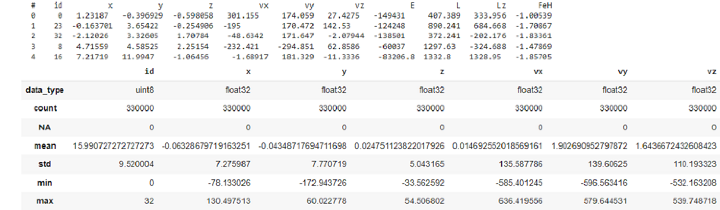
我們將使用 **vaex.example()** 命令直接載入 Vaex 提供的以 HDF5 格式儲存的記憶體對映資料集。
示例
import vaex %time df_v=vaex.example() print(df_v.head(5)) df_v.describe()
輸出
CPU times: user 10.7 ms, sys: 0 ns, total: 10.7 ms Wall time: 10.7 ms
Pandas 的效能
我們將載入 Vaex 使用的相同資料集,並比較其讀取效能。
示例
import pandas as pd
columns = df_v.get_column_names()
data = {}
for column in columns:
data[column] = df_v[column].values
%time df_p = pd.DataFrame(data)
print(df_p.head(5))
df_p.describe()
輸出
CPU times: user 4.17 ms, sys: 5.06 ms, total: 9.23 ms Wall time: 13.7 ms
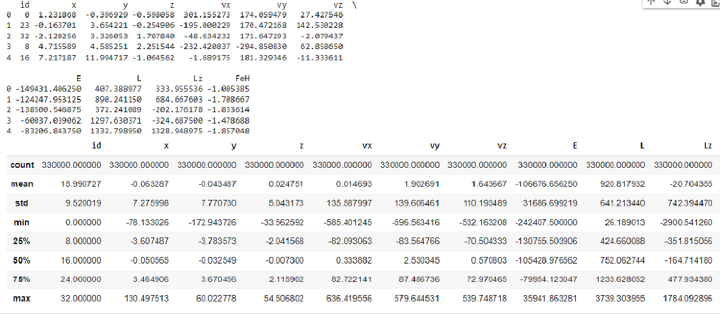
從以上結果可以得出結論,對於相同的資料集,Vaex 的花費時間比 Pandas 少。
示例
print("Size =")
print(df_p.shape)
print(df_v.shape)
輸出
Size = (330000,11) (330000,11)
使用 Vaex 進行資料操作/延遲計算
Vaex 使用一種稱為“延遲評估”的技術,將操作的評估延遲到需要其結果時。此技術有助於節省計算能力並有效地管理記憶體。正如我們所知,Vaex 使用表示式系統,這些表示式被延遲評估,這意味著計算僅在必要時才執行。這樣可以使計算更快。讓我們用一個關於單一計算的示例來測試它:
Pandas DataFrame
示例
%time df_pandas['x'] + df_pandas['y']
輸出
CPU times: user 2.15 ms, sys: 10 µs, total: 2.16 ms Wall time: 1.51 ms
Vaex DataFrame
示例
%time df_v.x + df_v.y
輸出
CPU times: user 280 µs, sys: 31 µs, total: 311 µs Wall time: 318 µs Expression = (x + y) Length: 330,000 dtype: float32 (expression) ------------------------------------------- 0 0.83494 1 3.49052 2 1.2058 3 9.30084 4 19.2119 ... 329995 2.78315 329996 4.43943 329997 13.3985 329998 1.34032 329999 17.4648
統計效能
Vaex 還可以執行一些操作,例如均值、標準差、計數等。讓我們比較 pandas 和 Vaex 在計算統計資料時的效能:
Pandas Dataframe
示例
%time df_p["L"].mean()
輸出
Wall time:4.23 ms 920.81793
Vaex DataFrame
示例
%time df_v.mean(df_v.L)
輸出
Wall time: 2.49 ms array(920.81803276)
資料過濾
與 Pandas 不同,Vaex 在過濾、選擇、清理資料時不會建立記憶體副本。以資料過濾為例。由於 Vaex 不進行記憶體複製,因此它使用很少的 RAM 空間即可完成,並且執行速度也會很快。
Pandas Dataframe
示例
%time df_p_filtered = df_p[df_p['x'] > 0]
輸出
CPU times: user 13 ms, sys: 1.74 ms, total: 14.7 ms Wall time: 19.7 ms
Vaex Dataframe
示例
%time df_v_filtered = df_v[df_v['x'] > 0]
輸出
CPU times: user 1.23 ms, sys: 20 µs, total: 1.25 ms Wall time: 1.27 ms
Vaex 透過在對資料進行單次傳遞時執行多個計算來展示其效率:
示例
df_v.select(df_v.id < 15,name='less_than') df_v.select(df_v.id >= 15,name='greater_than') %time df_v.mean(df_v.id, selection=['less_than', 'greater_than'])
輸出
CPU times: user 19.3 ms, sys: 0 ns, total: 19.3 ms Wall time: 15.5 ms array([ 7.00641717, 23.49799197])
Vaex 中的虛擬列
如果我們希望透過結合表示式在資料幀中建立新列,則虛擬列就會發揮作用。這些列類似於常規列,但不會佔用記憶體空間;相反,它們儲存表示式本身。在 Vaex 的世界中,虛擬列和常規列之間沒有區別,因為預設的表示式系統平等地對待它們。
示例
%time df_v['new_col'] = df_v['x']**2 print(df_v.head()) df_v.mean(df_v['new_col'])
輸出
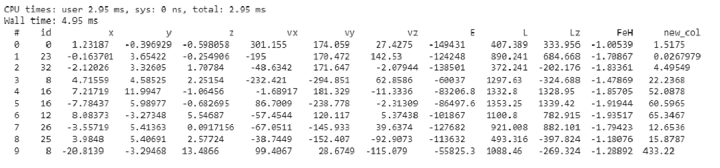
正如您所觀察到的,一個新列被新增到表中。
array(52.94398942)
視覺化
Vaex 與流行的視覺化庫(如 Matplotlib 和 Bokeh)無縫整合,使使用者能夠使用大型資料集建立高度詳細且互動式的視覺化。
Vaex 是一款功能強大的資料分析庫,使使用者能夠輕鬆建立令人驚歎的視覺化效果,超越了二維表示的界限,深入到 **錯綜複雜的 3D 景象領域**,即使在 **處理海量** 和 **複雜** 資料集時也是如此。
我們將嘗試建立一個一維圖形:
示例
%time df_v.viz.histogram(df_v.x, limits = [0, 10])
輸出
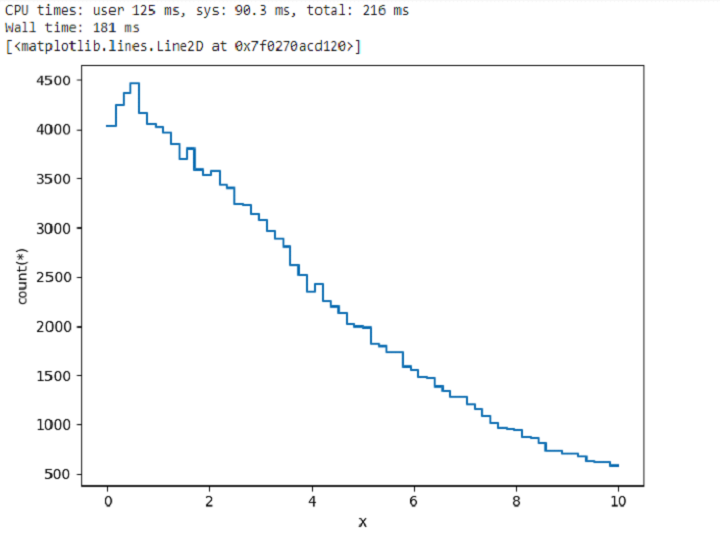
我們將嘗試建立一個二維圖形:
示例
df_v.viz.heatmap(df_v.x,df_v.y+df_v.z,limits=[-3, 20])
輸出
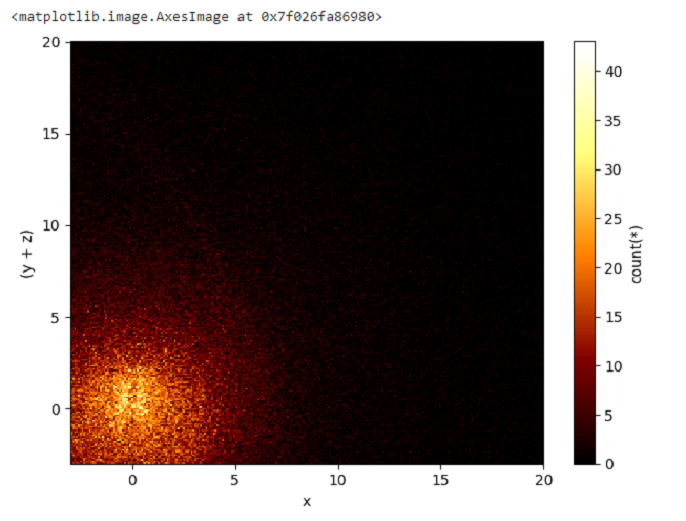
此外,我們還可以新增一些統計表達式來視覺化資料。可以使用以下 **語法** 傳遞表示式:
語法
what=<statistic><Expression> as an argument.
輸出
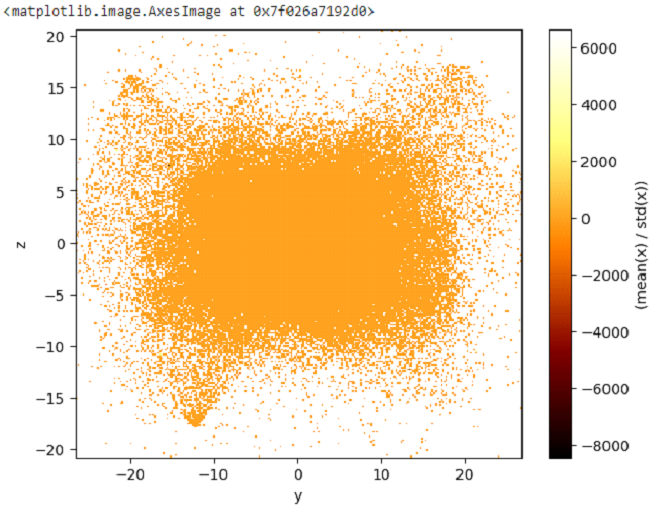
我們還可以將算術運算和 NumPy 函式新增到這些計算中。

190 次檢視
