
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 語言程式設計
C 語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJavaScript 中的非同步程式碼是如何工作的?
在本文中,我們將探討非同步程式碼在JavaScript中的實際工作方式,包括其初始化、執行和呼叫過程。但在繼續之前,讓我們先了解一下同步程式碼是什麼,以及它與非同步程式碼有何不同。
同步程式碼 - 這意味著使用者按順序獲取同步呼叫和訪問的資料。使用者呼叫方法後,方法才會執行並進行檢查。
在非同步程式碼中,觸發器由使用者或系統觸發。觸發函式的人並不重要,一旦函式被觸發,它就會給出響應,而無需完成執行。例如:從伺服器下載檔案。
非同步函式也有一個呼叫棧,它接收方法呼叫並記錄它們。這將遵循LIFO結構,即後進先出,其中每個任務函式都透過移除堆疊頂部存在的任何內容來執行。
示例 1
在下面的示例中,我們建立了一個非同步程式碼並檢查其工作方式。
非同步資料的主要目的是為使用者提供更快的訪問速度,並在後臺執行其操作。
這種方法在使用使用資源或嘗試從 API 本身收集響應的 API(應用程式程式設計介面)時非常有用。
為了處理非同步資料,我們在 JavaScript 中使用 Promise 或回撥函式。這些 Promise 或回撥函式可以輕鬆地從 API 獲取響應或資料。
它還使用呼叫棧來記錄事件以及接下來要呼叫的函式。我們還有事件迴圈、Web API 和訊息佇列來促進非同步程式設計。
任何同步方法或 DOM 事件都使用 Web API 來呼叫函式。但在非同步呼叫中,我們將訊息釋出到佇列中,該佇列將在後臺自動執行。
事件迴圈執行的任務基本上取決於堆疊是否為空。如果堆疊不為空,則該特定事件迴圈將資料從佇列獲取到呼叫堆疊以進行執行。
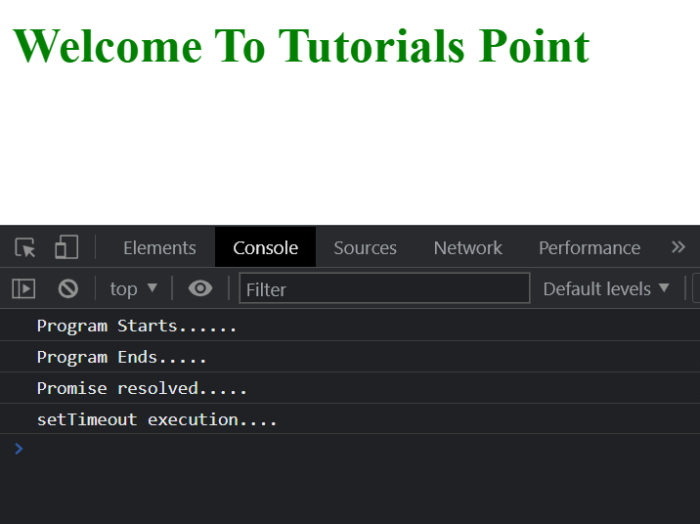
# index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Asynchronous Code</title>
</head>
<body>
<h1 style="color: green;">
Welcome To Tutorials Point
</h1>
<script>
console.log("Program Starts......");
setTimeout(() => {
console.log("setTimeout execution....");
}, 0);
new Promise((resolve, reject) => {
resolve("Promise resolved.....");
})
.then((res) => console.log(res))
.catch((error) => console.log(error));
console.log("Program Ends.....");
</script>
</body>
</html>輸出

更新於:2022年4月22日
271 次瀏覽

廣告