
 資料結構
資料結構 網路
網路 關係資料庫管理系統 (RDBMS)
關係資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 語言程式設計
C 語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPSeaborn 如何處理資料以建立圖表?
在 Seaborn 中,資料處理是使用 pandas 完成的,pandas 是 Python 中一個流行的資料處理庫。Seaborn 基於 pandas 構建,並與其無縫整合。Pandas 提供強大的資料結構和函式來進行資料處理,例如過濾、分組、聚合和轉換資料,這些都可以與 Seaborn 結合使用來建立圖表。
透過結合 pandas 的資料處理能力和 Seaborn 的繪圖功能,我們可以輕鬆地以簡潔高效的方式處理和視覺化資料。這使我們能夠有效地探索和傳達資料集中的見解。
這是一個關於如何使用 Seaborn 中的 Pandas 庫進行資料處理以建立圖表的逐步指南。
匯入必要的庫
由於我們使用的是 pandas 和 Seaborn 庫,因此我們首先需要使用以下程式碼匯入這兩個庫。
import seaborn as sns import pandas as pd
使用 pandas 載入或建立資料集
接下來,我們可以使用 pandas 庫的 read_csv 和 DataFrame 載入或建立我們自己的資料集。在這篇文章中,我們使用 pandas 庫的 DataFrame() 函式建立資料集。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
print(df.head())
輸出
Name Age Salary 0 Alice 25 50000 1 Bob 30 60000 2 Charlie 35 70000
執行資料處理操作
一旦我們擁有 pandas DataFrame 中的資料集,現在我們可以使用各種資料處理技術來準備繪圖資料。一些常見操作如下所示。
過濾
過濾用於根據特定條件選擇子集的行或列。例如,如果我們想從建立的資料中過濾年齡大於 30 的行,則程式碼將定義如下。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
df.head()
filtered_df = df[df['Age'] > 30]
res = filtered_df.head()
print(res)
輸出
Name Age Salary 2 Charlie 35 70000
分組和聚合
根據一個或多個變數對資料進行分組並計算彙總統計資訊。例如,如果我們想按姓名分組並計算平均工資,則將使用以下程式碼行。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
grouped_df = df.groupby('Name')['Salary'].mean()
print(grouped_df.head())
輸出
Name Alice 50000.0 Bob 60000.0 Charlie 70000.0 Name: Salary, dtype: float64
資料轉換
資料轉換意味著應用函式或轉換來修改資料並根據現有列建立新列。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
df.head()
grouped_df = df.groupby('Name')['Salary'].mean()
res = grouped_df.head()
print(res)
輸出
Name Alice 50000.0 Bob 60000.0 Charlie 70000.0 Name: Salary, dtype: float64
資料重塑
在資料重塑中,我們使用諸如透視或熔化之類的技術將資料重構為不同的格式。
示例
import seaborn as sns
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
pivoted_df = df.pivot(index='Name', columns='Age', values='Salary')
print(pivoted_df.head())
輸出
Age 25 30 35 Name Alice 50000.0 NaN NaN Bob NaN 60000.0 NaN Charlie NaN NaN 70000.0
使用 Seaborn 建立圖表
資料準備完成後,我們可以使用 Seaborn 的繪圖函式根據我們的資料建立視覺化效果。例如,如果我們想建立按年齡組劃分的平均工資條形圖,則
示例
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Salary': [50000, 60000, 70000]}
df = pd.DataFrame(data)
sns.barplot(x='Age', y='Salary', data=df)
plt.show()
輸出
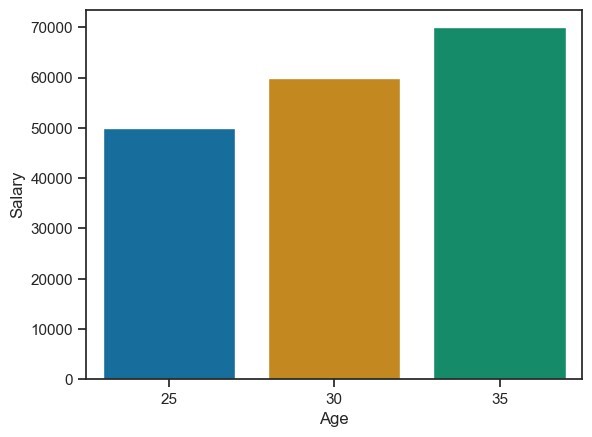
Seaborn 提供各種繪圖函式,包括散點圖、折線圖、條形圖、直方圖、箱線圖等等。這些函式接受 pandas DataFrame 作為輸入,並提供選項來自定義圖表的顯示和樣式。

瀏覽量:110
