
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在檔案中查詢與輸入句子最相似的句子 | NLP
自然語言處理 (NLP) 允許計算機解釋和分析人類語言。查詢與給定輸入句子最相同的單詞或句子是一個普遍的 NLP 問題。在 Python 中,有多種方法可以查詢相同的句子。
所需資源
要完成此操作,您必須在系統中安裝 nltk 庫。因此,在您的 Python 命令提示符中執行以下命令以安裝 nltk。
pip install nltk
如果上述命令無法執行,您也可以在 Windows cmd 中執行以下命令。
python --version pip --version pip install nltk
成功安裝庫後,我們可以在程式碼中匯入它,並使用 nltk 中的各種模組來編寫句子查詢程式。
示例
我們將建立一個 Python 程式,該程式從使用者那裡獲取輸入句子,並從檔案中查詢最相似的句子。讓我們探索如何使用 Python NLTK 包來實現這一點。我們將專門使用 TF-IDF (詞頻-逆文件頻率) 方法和各種 NLP 預處理步驟。
演算法
步驟 1:安裝並匯入 NLTK。您可以使用上面解釋的任何方法。
步驟 2:編寫程式碼以從檔案中載入句子。載入句子,然後處理它們以生成預處理句子的列表,每個句子都去除任何前導或尾隨空格。
步驟 3:處理輸入句子和檔案的已去除空格的句子。
步驟 4:執行分詞以將每個句子分解成單詞。
步驟 5:從句子中刪除停用詞以比較主要單詞。
步驟 6:比較單詞併為它們分配權重以查詢權重最高的單詞。這樣做,您可以找到檔案中最相似的句子。
示例
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
# Download NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('wordnet')
# Load the file containing sentences
def load_sentences(file_path):
with open(file_path, 'r') as file:
sentences = file.readlines()
return [sentence.strip() for sentence in sentences]
# Preprocess the input sentence
def preprocess_sentence(sentence):
# Tokenize
tokens = word_tokenize(sentence.lower())
# Remove stopwords
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
# Lemmatize
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return ' '.join(tokens)
# Get the most similar sentence
def get_most_similar_sentence(user_input, sentences):
# Preprocess input sentence
preprocessed_user_input = preprocess_sentence(user_input)
# Preprocess sentences
preprocessed_sentences = [preprocess_sentence(sentence) for sentence in
sentences]
# Create TF-IDF vectorizer
vectorizer = TfidfVectorizer()
# Generate TF-IDF matrix
tfidf_matrix = vectorizer.fit_transform([preprocessed_user_input] +
preprocessed_sentences)
# Calculate similarity scores
similarity_scores = (tfidf_matrix * tfidf_matrix.T).A[0][1:]
# Find the index of the most similar sentence
most_similar_index = similarity_scores.argmax()
most_similar_sentence = sentences[most_similar_index]
return most_similar_sentence
# Main program
def main():
file_path = 'sentences.txt' # Path to the file containing sentences
sentences = load_sentences(file_path)
user_input = 'hello I am a women'
most_similar_sentence = get_most_similar_sentence(user_input, sentences)
print('Most similar sentence:', most_similar_sentence)
if __name__ == '__main__':
main()
文字檔案內容:Sentences.txt
這是一部喜劇電影。
這是一部恐怖電影。
你好,我是一個女孩。
你好,我是一個男孩。
輸出
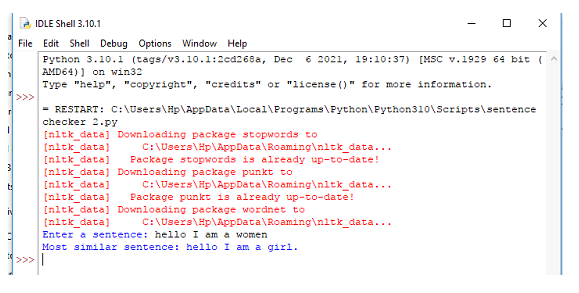
結論
我們已經體驗了使用 NLTK 庫和 NLP 方法來發現與給定輸入文字最相似的句子的方法。透過使用 TF-IDF 方法和諸如分詞、停用詞去除和詞形還原之類的預處理技術,我們可以有效地比較句子並找到最接近的匹配。
您可以在任何應用程式或程式中使用這種方法來新增句子相似性檢查功能,該功能可用於關聯使用者輸入的有用資訊。

444 次檢視
