
 資料結構
資料結構 網路
網路 關係型資料庫管理系統
關係型資料庫管理系統 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 程式設計
C 程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJava 中 SAX 解析器和 DOM 解析器的區別
SAX 和 DOM 都是 XML 解析器 API 的一種型別。這裡,API 代表應用程式程式設計介面,解析器用於以所需的格式讀取和提取 XML 文件中的內容。從這句話可以看出,SAX 和 DOM 用於讀取 XML 文件。
API 是在 Web 上遷移即時資訊的一種現代方法。在本文中,我們將討論 Java 中 SAX 和 DOM 解析器的區別。
XML 解析器型別
在進一步探討本文之前,讓我們簡要討論一下 XML 及其型別。
XML
它的全稱是可擴充套件標記語言,據說是一種資料描述語言。在其中,使用者可以根據需要定義自己的標籤。它以樹形結構儲存資訊,使其簡單易懂。
這是一個 XML 文件示例
<?xml version="1.0"?>
<grocery>
<cart id = "c101">
<item> Milk </item>
<price> 65 </price>
<quantity> 15 </quantity>
</cart>
<cart id = "c102">
<item> Bread </item>
<price> 30 </price>
<quantity> 10 </quantity>
</cart>
<cart id = "c103">
<item> Butter </item>
<price> 40 </price>
<quantity> 5 </quantity>
</cart>
</grocery>
將資料從一個源傳輸到另一個源需要轉換資料格式。透過 DOM 和 SAX 等解析方法,我們可以讀取並將 XML 資料轉換為所需的格式。
SAX 解析器
它是 XML 簡單 API 的縮寫。它從頭到尾逐行讀取 XML 文件。每當它在解析過程中遇到任何標籤時,它都會呼叫該方法併為使用者檢索資訊。
例如,假設我們想從 XML 文件中訪問地址,並且該文件中有一個名為“address”的標籤。在這種情況下,當 SAX 解析器到達該標籤時,它將呼叫該方法來檢索地址。
SAX 解析器的介面
SAXParserFactory − 它是解析器的物件,是解析的第一步
SAXParser − 它定義了一個名為“parse()”的方法,用於解析。
SAXReader − 它處理與 SAX 事件處理程式的通訊。
DOM 解析器
它是文件物件模型的縮寫,由全球資訊網聯盟 (W3C) 開發。首先,它讀取整個 XML 文件並將整個文件轉換為樹的形式儲存在記憶體中。這棵樹有一個根節點和多個父節點和子節點。下圖描繪了上面 XML 文件的樹 -
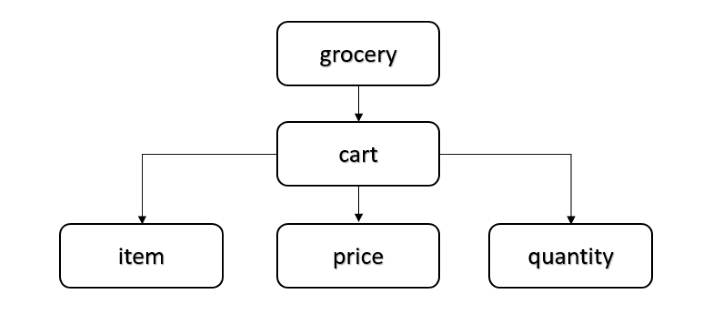
在上圖中,“grocery”是根節點。“cart”是父節點,其餘節點是其子節點。
我們建立了一個名為 DocumentBuilder 的 DocumentBuilderFactory 介面例項,該介面具有一個內建的 parse 方法,該方法將 XML 文件作為引數並將其轉換為 DOM 樹。
SAX 和 DOM 解析器的區別
從上面的討論中,我們可以得出 SAX 和 DOM 解析器之間以下區別 -
SAX 解析器 |
DOM 解析器 |
|---|---|
它是 XML 文件的簡單 API。 |
它是文件物件模型。 |
它由 XML-Dev 成員開發。 |
它由全球資訊網聯盟 (W3C) 開發。 |
SAX 基於事件模型工作。 |
DOM 基於樹模型工作。 |
它只能對 XML 文件執行讀取操作。 |
它是雙向的,可以對 XML 文件執行讀取和寫入操作。 |
SAX 以自上而下的方式讀取 XML 檔案,無法提供隨機訪問。 |
它更適合複雜和隨機訪問。 |
它記憶體效率高,可以處理大型 XML 檔案。 |
它記憶體效率不高,不適合處理大型檔案。 |
它從開始處理給定的文件,從而減少了解析的等待時間。 |
從開始處理給定的文件,從而減少了解析的等待時間。在解析之前,它會建立一個 DOM 樹。因此,應用程式必須等到樹建立完成。 |
結論
在本文中,我們區分了 SAX 和 DOM 解析器。在此過程中,我們發現了 XML,它是一種資料描述語言。它提供各種解析器,如 StAX、DOM 和 SAX,用於讀取和寫入 XML 檔案。所有解析器在許多方面都相似,但區別在於它們的功能和工作方式。此外,它們也各有優缺點。

3K+ 閱讀量
