
 資料結構
資料結構 網路
網路 關係型資料庫管理系統 (RDBMS)
關係型資料庫管理系統 (RDBMS) 作業系統
作業系統 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C語言程式設計
C語言程式設計 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在ScrapingHub上部署Scrapy爬蟲
Scrapy爬蟲
Scrapy爬蟲是一個類,它提供了一種跟蹤網站連結並從網頁中提取資訊的功能。
這是其他爬蟲必須繼承的主要類。
Scrapinghub
Scrapinghub是一個開源應用程式,用於執行Scrapy爬蟲。Scrapinghub將網路內容轉換成一些有用的資料或資訊。它允許我們從網頁中提取資料,即使是複雜的網頁。
我們將使用scrapinghub將scrapy爬蟲部署到雲端並執行它。
在scrapinghub上部署爬蟲的步驟:
步驟1:
建立一個scrapy專案:
安裝scrapy後,只需在終端中執行以下命令:
$scrapy startproject <project_name>
將您的目錄更改為新專案 (project_name)。
步驟2:
為您的目標網站編寫一個scrapy爬蟲,讓我們以一個常見的網站“quotes.toscrape.com”為例。
下面是我的一個非常簡單的scrapy爬蟲:
程式碼:
#import scrapy library
import scrapy
class AllSpider(scrapy.Spider):
crawled = set()
#Spider name
name = 'all'
#starting url
start_urls = ['https://tutorialspoint.tw/']
def __init__(self):
self.links = []
def parse(self, response):
self.links.append(response.url)
for href in response.css('a::attr(href)'):
yield response.follow(href, self.parse)步驟3:
執行您的爬蟲並將輸出儲存到您的links.json檔案:
執行上述程式碼後,您將能夠抓取所有連結並將其儲存到links.json檔案中。這可能不是一個漫長的過程,但是為了持續執行24/7,我們需要將這個爬蟲部署到Scrapinghub。
步驟4:
在Scrapinghub上建立帳戶
為此,您只需使用您的Gmail帳戶或Github登入ScrapingHub登入頁面即可。它將重定向到儀表板。
現在單擊“建立專案”並提及專案的名稱。現在我們可以使用命令列(CLI)或透過github將專案新增到雲端。接下來我們將透過shub CLI部署我們的程式碼,首先安裝shub
$pip install shub
安裝shub後,使用建立帳戶時生成的API金鑰登入shub帳戶(從https://app.scrapinghub.com/account/apikey輸入您的API金鑰)。
$shub login
如果您的API金鑰正確,您現在已登入。現在我們需要使用在“部署您的程式碼”部分的命令列部分看到的部署ID(6位數字)來部署它。
$ shub deploy deploy_id
這就是命令列的方法,現在回到“爬蟲”儀表板部分,使用者可以看到已準備好的爬蟲。只需單擊爬蟲名稱和“執行”按鈕即可。現在您可以在儀表板中看到您的爬蟲,如下所示:
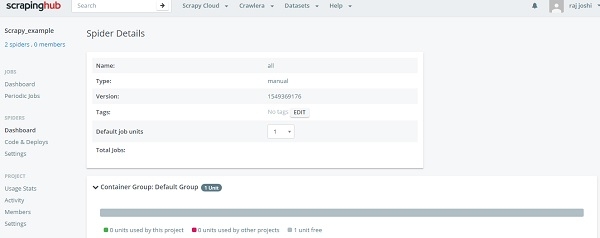
它將透過一次點擊向我們展示執行進度,您無需讓本地機器24/7執行。

154 次瀏覽
